1# Using realtime models1# Using realtime models
2 2
3Realtime models are post-trained for specific customer use cases. In response to your feedback, the latest speech-to-speech model works differently from previous models. Use this guide to understand and get the most out of it.3`gpt-realtime-2` is our state-of-the-art reasoning voice model for low-latency speech-to-speech applications. It can think before it speaks, follow instructions more reliably, use a larger context window, and call tools with greater precision than earlier realtime models.
4
5To take advantage of these gains, design prompts with more intent. Define the assistant's responsibilities, decision points, tool-calling behavior, and guardrails clearly: what it should do, when it should do it, and what it should avoid.
6
7Start simple. Do not over-prompt upfront. Begin with a minimal prompt, run
8 evaluations, then add instructions only for behaviors that fail in testing.
9
10## Choose a model
11
12<table>
13 <thead>
14 <tr>
15 <th>Model</th>
16 <th>Use when</th>
17 <th>Prompting focus</th>
18 </tr>
19 </thead>
20 <tbody>
21 <tr>
22 <td style={{ whiteSpace: "nowrap" }}>
23 <a href="/api/docs/models/gpt-realtime-2">
24 <code>gpt-realtime-2</code>
25 </a>
26 </td>
27 <td>
28 You need the strongest realtime reasoning, tool use, and instruction
29 following.
30 </td>
31 <td>
32 Tune reasoning effort, preambles, tool policies, exact entity capture,
33 and long-session state.
34 </td>
35 </tr>
36 <tr>
37 <td style={{ whiteSpace: "nowrap" }}>
38 <a href="/api/docs/models/gpt-realtime-1.5">
39 <code>gpt-realtime-1.5</code>
40 </a>
41 </td>
42 <td>You need a fast, reliable non-reasoning speech-to-speech model.</td>
43 <td>
44 Follow the core realtime prompt structure and test for latency-sensitive
45 behavior.
46 </td>
47 </tr>
48 </tbody>
49</table>
50
51
52
53<div data-content-switcher-pane data-value="gpt-realtime-2">
54## Realtime 2.0 Prompting Guide
55
56 <p>
57 Use <code>gpt-realtime-2</code> when the voice agent needs stronger
58 reasoning, tool selection, exact entity handling, or long-session state.
59 Start with <code>reasoning.effort: "low"</code>, test default preamble
60 behavior, and define clear confirmation boundaries before write actions.
61 </p>
62
63## What changed in Realtime 2
64
65Prompt Realtime 2 as a reasoning voice agent, not as a basic voice bot.
66
67| Change | What it means for prompts |
68| ------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------- |
69| Reasoning | Allow the model to reason internally for complex tasks before speaking or calling tools. Use preambles to avoid awkward silence or unnecessary filler. |
70| Prompt precision matters more | Replace broad guidance like "be helpful" with clear trigger, action, and exception rules: when to act, what to do, and when not to do it. |
71| Instruction conflicts are more costly | Remove overlapping `always`, `never`, `only`, and `must` rules unless they are truly required. Define priority when rules compete. |
72| Tool behavior is more steerable | Specify when the assistant should act immediately, ask for missing information, confirm high-precision details, retry after failure, or escalate. |
73| Preambles are first-class behavior | The model may speak brief updates before longer reasoning or tool-use flows. Steer when preambles should appear, how short they should be, and when to skip them. |
74| Expanded context window | `gpt-realtime-2` expands the realtime context window from 32k to 128k tokens, making it better suited for long sessions and larger system prompts. |
75
76Preambles aren't hidden chain-of-thought. They're short spoken updates such as
77 "I'll check that order now." Don't ask the model to reveal private reasoning.
78
79## Recommended prompt structure
80
81Use short, labeled sections. The model should be able to find the relevant instructions quickly.
82
83```text
84# Role and Objective
85
86# Personality and Tone
87
88# Language
89
90# Reasoning
91
92# Message Channels
93
94# Preambles
95
96# Verbosity
4 97
5## Meet the models98# Tools
99
100# Unclear Audio
101
102# Entity Capture
103
104# Long Context Behavior
105
106# Escalation
107```
108
109Not every use case needs every section. Add the sections that are relevant for your product.
110
111## Set reasoning effort
112
113`gpt-realtime-2` can trade latency for deeper reasoning. Use the lowest reasoning level that still gives the assistant enough intelligence for the workflow.
114
115Start with `low` for most production voice agents. Tune up or down based on task complexity, latency tolerance, and failure cost.
116
117| Effort | Use when | Example |
118| --------- | --------------------------------------------------- | ----------------------------------------------------------------------- |
119| `minimal` | Lowest latency matters most and the task is simple. | Smart-home commands, timers, simple calendar checks. |
120| `low` | You need responsiveness plus basic reasoning. | Customer support, order lookup, simple policy questions. |
121| `medium` | The assistant must reason through multi-step tasks. | Technical support, diagnostics, complex routing. |
122| `high` | Deeper reasoning materially improves success. | High-precision workflows, escalation decisions, tasks with constraints. |
123
124Beyond the API setting, steer the model on when and how much to reason.
125
126```text
127## Reasoning
128
129- For direct answers, simple lookups, and short confirmations, respond quickly and do not reason.
130- For multi-step tasks, tool decisions, troubleshooting, or escalation, reason before acting.
131- Do not perform extended reasoning when the user's audio is unclear; ask for clarification instead.
132```
133
134## Use preambles intentionally
135
136Preambles are short spoken updates that keep a voice agent feeling responsive while it reasons, looks something up, or calls a tool. Used well, they reassure the user that the assistant is working. Used poorly, they become filler and increase perceived latency.
137
138`gpt-realtime-2` generates preambles by default. Start by testing the default behavior. If it does not match your product experience, tune it explicitly.
139
140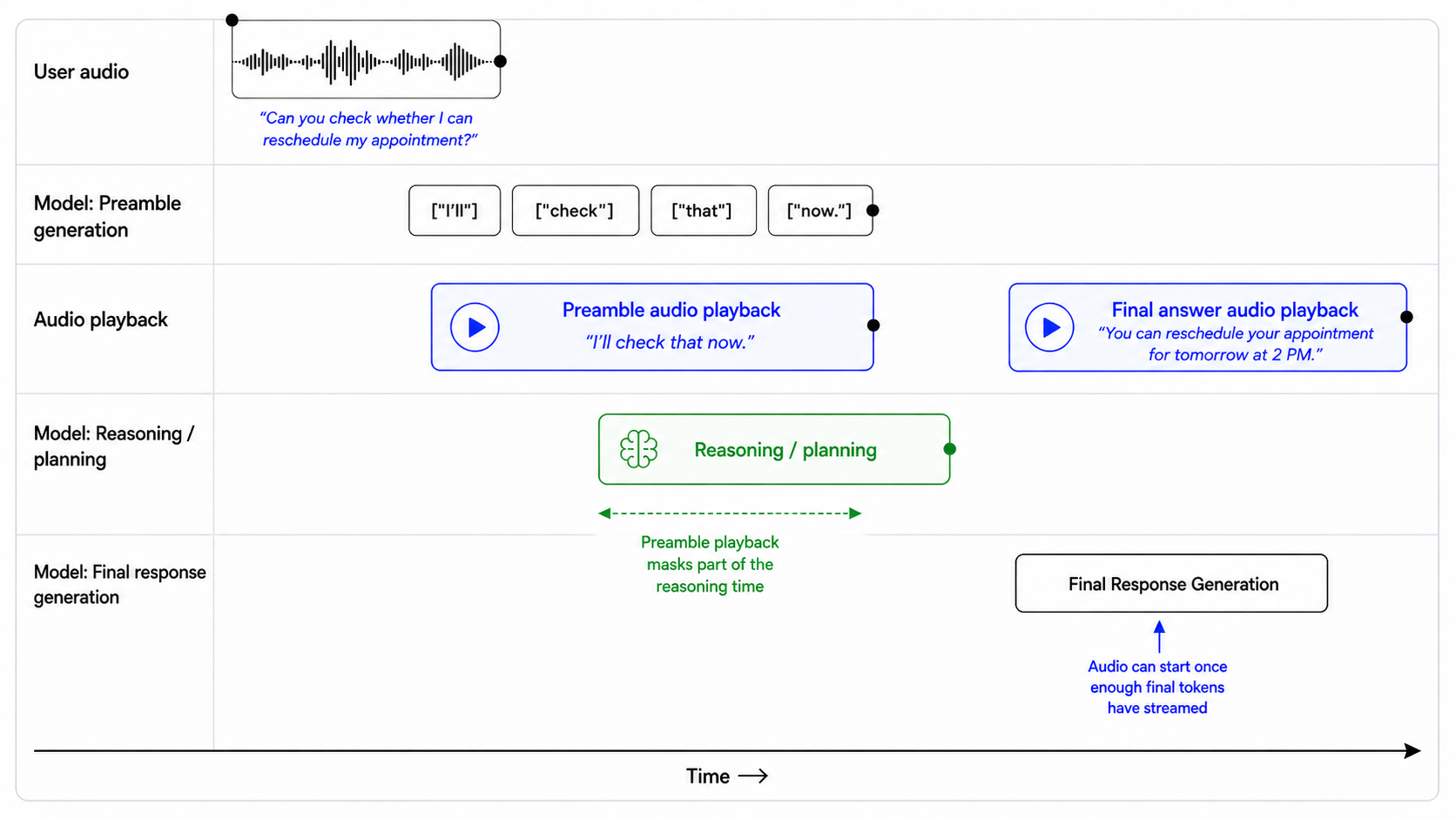
141
142```text
143## Preambles
144
145Use short preambles only when they help the user understand that work is happening.
146
147### When to use a preamble
148
149Use a preamble when:
150
151- you are about to call a tool that may take noticeable time;
152- you need to reason through a multi-step request;
153- you are checking records, availability, account state, or policy details;
154- you are preparing an escalation or handoff;
155- silence would make the assistant feel unresponsive.
156
157When a preamble is needed, output it immediately before substantive reasoning or tool use.
158
159### When to not use a preamble
160
161Do not use a preamble when:
162
163- the answer is direct and can be given immediately;
164- the user is only confirming, correcting, or declining something;
165- the audio is unclear and you need clarification;
166- the latest audio is silence, background noise, hold music, TV audio, or side conversation;
167- the tool call is lightweight and the user would not benefit from an update.
168
169### Preamble style
170
171When using a preamble:
172
173- keep it natural, calm, and concise;
174- vary the wording across turns;
175- describe the action, not the internal reasoning;
176- avoid filler.
177
178Avoid phrases like:
179
180- "Let me think..."
181- "Hmm..."
182- "One moment while I process that..."
183- "I am now going to access the tool..."
184
185### Preamble length
186
187Use one short sentence.
188
189Do not exceed two short sentences unless the user needs an explanation before a high-impact action.
190
191### Prefer
192
193- "I'll check that order now."
194- "I'll look up your appointment details."
195- "I'll verify that before we make any changes."
196- "I'll check the policy and then give you the next step."
197- "I'll pull that up so we can make sure it's the right account."
198
199### Avoid
200
201- "Let me think about that for a second."
202- "Please wait while I process your request."
203- "I'm going to use my tools now."
204- "Interesting question. I will reason through this carefully."
205```
206
207## Control response length
208
209`gpt-realtime-2` follows length guidance best when the prompt specifies how much detail to give for each task type. Instead of telling the model to "be concise," define what concise means in context: direct answers, tool results, troubleshooting, comparisons, and escalations may each need different response lengths.
210
211```text
212## Verbosity
213
214- Direct answers: Use 1-2 short sentences.
215- Clarifying questions: Ask one question at a time.
216- Tool results: Summarize the result first, then give only the next useful action.
217- Product or option comparisons: Include key differences, tradeoffs, and who each option fits.
218- Troubleshooting: Give one step at a time unless the user asks for the full procedure.
219- Escalations: Briefly explain why escalation is needed and what will happen next.
220```
221
222Example:
223
224> User: Which plan should I choose?
225
226> Assistant: If you want the lowest cost, choose Basic. If you need team permissions and shared billing, choose Pro. If compliance review or admin controls matter, choose Enterprise.
227
228## Design tool behavior
229
230`gpt-realtime-2` is stronger at tool calling, but tool behavior still depends on prompt and tool-spec design. If the prompt does not define when to act, ask, confirm, or recover, the assistant may call tools too early, ask unnecessary questions, or repeat failed calls.
231
232### Set tool-call eagerness
233
234High eagerness works well for read-only, low-risk actions. Low eagerness is better when tools modify data, trigger external effects, or depend on exact identifiers.
235
236| Tool type | Default behavior |
237| ----------------------------------- | --------------------------------------------------------- |
238| Read-only, low-risk lookup | Call when intent and required fields are clear. |
239| Read-only with exact identifier | Confirm the identifier before lookup. |
240| User-visible communication | Draft or summarize before sending. |
241| Account changes | Confirm before calling. |
242| Purchases, cancellations, payments | Confirm amount, target, and consequence before calling. |
243| Irreversible or high-impact actions | Confirm explicitly and offer escalation when appropriate. |
244
245Use this balanced default when you have a mix of read and write actions. Tailor it based on your use case.
246
247```text
248## Tools
249
250Use only the tools explicitly provided in the current tool list. Do not invent, assume, simulate, or rename tools.
251
252For read-only tools:
253
254- Call the tool when the user's intent is clear and all required fields are available.
255- Do not ask for confirmation unless the lookup depends on a high-precision identifier or there is meaningful risk of using the wrong record.
256- Ask a clarification question only if a required field is missing, ambiguous, or conflicting.
257
258For write tools or external actions:
259
260- Summarize the intended action before calling the tool.
261- Include the key consequence, such as what will be changed, sent, canceled, ordered, or charged.
262- Ask for confirmation.
263- Do not call the tool until the user clearly confirms.
264
265For exact identifiers:
266
267- Treat order IDs, tracking numbers, account numbers, confirmation codes, phone numbers, and email addresses as high precision.
268- Normalize only when the field type is clear.
269- Confirm the final value before account-specific lookups, validation, or write actions.
270
271After tool calls:
272
273- Only say an action was completed after the tool call succeeds.
274- If the tool fails, explain the failure briefly, avoid raw errors, and give the user a clear next step.
275```
276
277High-risk example:
278
279> User: Charge my card for the remaining balance.
280
281Bad:
282
283> Assistant: I've charged your card.
284
285Good:
286
287> Assistant: To confirm, you want me to charge the card on file $248.16 for the remaining balance. Should I proceed?
288
289### Recover from tool failures
290
291Tool failures are part of the conversation. A good recovery should explain what happened and give the user a clear next step.
292
293Do not treat every failure the same. Recovery behavior should depend on the tool type, failure mode, and user impact. Some failures should be handled silently with a retry. Others require asking the user to clarify, correct an identifier, confirm a new action, or choose an alternate path.
294
295```text
296## Tool Failures
297
298If a tool call fails:
299
3001. Briefly explain what failed in user-friendly language.
3012. Do not blame the user or expose raw tool errors.
3023. If the failure may be due to an exact identifier, read back the value used and ask the user to correct it.
3034. If the failure may be temporary, offer to retry once.
3045. If the same failure happens repeatedly, offer an alternate path or escalation.
305
306Do not repeatedly call the same tool with the same arguments after failure.
307
308Do not ask for a different identifier until you have first checked whether the captured value was correct.
309```
310
311Bad:
312
313> Assistant: Something went wrong.
314
315Good:
316
317> Assistant: I couldn't find a match for O R D dash 3 1 2 5 B 2 3. Did I get any part of that wrong?
318
319### Keep tool availability synchronized
320
321Realtime models are eager to help. If the prompt mentions a tool that is not actually available, or if the tool list does not match the prompt, the model may invent a tool name or pretend it completed the action.
322
323For example, if the prompt references `lookup_order`, but the provided tool is named `search_orders`, the model may call the wrong name or simulate the action.
324
325```text
326## Tool Availability
327
328Use only the tools that are explicitly provided in the current tool list.
329
330Do not invent, assume, or simulate tools. If a tool is mentioned in the instructions but is not present in the tool list, treat it as unavailable.
331
332If the user requests an action that requires an unavailable tool:
333
3341. Do not pretend to complete the action.
3352. Briefly explain that the tool is not available.
3363. Offer the closest supported next step.
337
338Only say an action was completed after the relevant tool call succeeds.
339```
340
341Use the prompt audit meta prompt in the appendix to review production prompts
342 for contradictions, missing tools, and brittle instructions.
343
344## Handle silence and background audio
345
346Voice agents tend to respond by default. In production, they often hear audio that should not receive a spoken response, such as silence, background noise, hold music, TV audio, or side conversations.
347
348Use a no-op wait tool when the assistant should stay quiet and keep listening. The tool gives the model a valid non-speaking action instead of making it say things like "I'm here" or "I didn't catch that."
349
350Tool design:
351
352```json
353{
354 "name": "wait_for_user",
355 "description": "Call this when the latest audio does not need a spoken response, such as silence, background noise, hold music, TV audio, side conversation, or speech not addressed to the assistant. This tool helps end the turn without a spoken reply.",
356 "parameters": {
357 "type": "object",
358 "properties": {},
359 "required": []
360 }
361}
362```
363
364Pair it with prompt instructions:
365
366```text
367## Handling Silence and Background Noise
368
369If the latest audio is silence, background noise, hold music, TV audio, side conversation, or speech not addressed to you, call `wait_for_user`.
370
371Do not respond conversationally after calling this tool.
372
373Do not say "I'm here," "I didn't catch that," "Take your time," or "Let me know when you're ready."
374
375Resume normal responses only when the user clearly addresses you or asks for help.
376```
377
378Use this for non-addressed audio, not for unclear user requests. If the user is clearly speaking to the assistant but the content is unintelligible, ask for clarification instead.
379
380## Use message channels deliberately
381
382`gpt-realtime-2` can produce user-visible intermediate messages in the commentary channel and final user-facing responses in the final channel. Use channel-specific instructions when the behavior depends on where it appears.
383
384| Channel | User-visible? | Used for |
385| ------------ | ------------- | -------------------------- |
386| `commentary` | Yes | Preambles and tool calls. |
387| `final` | Yes | Final user-facing message. |
388
389For example, tool calls happen in the commentary channel. If you want the assistant to say something before, during, or after tool use, specify that behavior in relation to the commentary channel.
390
391```text
392Before calling tools in the commentary channel, briefly tell the user what you are doing.
393```
394
395`gpt-realtime-2` can emit multiple response phases in a single turn. In API output, this distinction is represented by the `response.done` event, which includes a `phase` value that indicates whether the content is commentary or the final answer.
396
397You can use this field to handle each phase differently in your application. For example, commentary can be played or displayed as a short intermediate update, while `final_answer` can be reserved for the assistant's completed response.
398
399```text
400response.output[0].phase: "commentary"
401response.output[1].phase: "final_answer"
402```
403
404Example response phases
405
406User prompt:
407
408> "I'm stuck on this AP Bio question [QUESTION]."
409
410Shortened API response:
411
412```json
413{
414 "type": "response.done",
415 "response": {
416 "output": [
417 {
418 "phase": "commentary",
419 "content": [
420 {
421 "type": "output_audio",
422 "transcript": "Let's zero in on the enzyme's shape and binding, since that's the key idea here."
423 }
424 ]
425 },
426 {
427 "phase": "final_answer",
428 "content": [
429 {
430 "type": "output_audio",
431 "transcript": "What changes at the active site at high temperature?"
432 }
433 ]
434 }
435 ]
436 }
437}
438```
439
440## Handle unclear audio
441
442The model should only act on audio it can understand with confidence. If the audio is unclear, the model should ask a brief clarification question instead of guessing.
443
444Do not let the model infer missing words, call tools, capture entities, generate preambles, or spend hidden reasoning time trying to reconstruct what the user may have said.
445
446```text
447## Unclear Audio
448
449- Only respond to clear audio or text.
450- If the user's audio is not clear, ask for clarification using a short English phrase such as "Sorry, could you repeat that clearly?"
451- Don't repeat the same unclear-audio clarification twice.
452- Treat audio as unclear if it is ambiguous, noisy, silent, unintelligible, partially cut off, or if you are unsure of the exact words the user said.
453- Do not guess what the user meant from unclear audio.
454- Do not reason when the audio is unclear.
455- Do not provide a preamble or call tools in the commentary channel when the audio is unclear.
456```
457
458Example:
459
460> User audio: "Check order three one-" [cut off]
461
462Bad:
463
464> Assistant: I'll check order 31 now.
465
466Good:
467
468> Assistant: I heard only part of the order number. Could you repeat it digit by digit?
469
470## Capture exact entities
471
472Many realtime workflows depend on exact values: order IDs, tracking numbers, email addresses, confirmation codes, account numbers, claim numbers, ticket IDs, support references, and phone numbers.
473
474Voice makes this hard. Users speak quickly, group numbers in different ways, spell partial values, use filler, correct themselves mid-turn, or pronounce characters that sound alike. One wrong digit can fail a lookup or retrieve the wrong account.
475
476Capture entities conservatively. Collect one value at a time, normalize only what is clear, confirm high-precision values before tool calls, and make every correction recoverable.
477
478### Collect one entity at a time
479
480When a workflow needs multiple values, collect them one at a time. This prevents fields from blending together, especially in voice conversations.
481
482```text
483## Entity Collection Order
484
485Collect required values one at a time.
486
487- Ask for only the next missing value.
488- Do not ask for multiple values in the same turn.
489- Before asking, check whether the value was already provided earlier in the conversation or the session.
490- If a possible value already exists, confirm it with the user before using it.
491
492Example:
493
494"I see tracking number ABC-54321 from earlier. Should I use that one, or do you have a different tracking number?"
495
496Do not call tools until the current value has been collected, validated, and confirmed.
497```
498
499### Handle spelled-out characters
500
501Use this when users spell IDs, codes, names, or email addresses one character at a time. The spoken form is input, not the final value.
502
503```text
504## Spelled-Out Characters
505
506When a user dictates an ID, code, or email character by character, treat the spoken sequence as one compact value. Preserve explicitly spoken separators like dash, dot, underscore, slash, or plus; otherwise do not add spaces or separators.
507
508Examples:
509
510- "A B C one two three" -> "ABC123"
511- "B C dash nine eight seven" -> "BC-987"
512- "J O H N at example dot com" -> "john@example.com"
513
514Do not insert spaces between spelled-out characters unless the user explicitly says the value contains spaces.
515```
516
517### Normalize spoken numbers carefully
518
519For numeric identifiers, users may say digits individually, group them, or use natural number phrases. If the field expects one continuous numeric value, convert clear numeric speech into digits.
520
521```text
522## Spoken Number Handling
523
524Convert spoken numbers into digits when collecting numeric identifiers.
525
526Examples:
527
528- "one two three four" -> "1234"
529- "one twenty three" -> "123"
530- "one nineteen" -> "119"
531- "ninety nine eleven" -> "9911"
532- "nine thousand nine hundred eleven" -> "9911"
533
534If multiple interpretations are plausible, ask the user to clarify before using the value.
535
536Example:
537
538"I heard either 119 or 1-19. Could you repeat the number digit by digit?"
539```
540
541### Confirm exact identifiers before tool calls
542
543Order IDs, tracking numbers, account numbers, claim numbers, confirmation codes, and similar identifiers are high-precision fields. Confirm them before using them in a tool call.
544
545For numeric identifiers, read the value back digit by digit. Reading the value as a full number can hide errors.
546
547Example:
548
549> Assistant: Just to confirm, I heard 8... 3... 5... 2... 1. Is that right?
550
551If the user corrects one character or digit, repeat the full corrected value before calling the tool.
552
553Example:
554
555> Assistant: Got it. I have 8... 3... 5... 7... 1. Is that correct?
556
557```text
558## Exact Identifier Confirmation
559
560Before calling tools with high-precision identifiers:
561
562- Confirm the final normalized value with the user.
563- Read numeric identifiers back digit by digit.
564- Do not use guessed, partial, or ambiguous values.
565- If the user corrects the value, repeat the full corrected value before calling the tool.
566```
567
568### Confirm emails character by character
569
570Email addresses are important values. Dots, dashes, underscores, repeated letters, and similar-sounding names can cause account lookup failures or send messages to the wrong address.
571
572Ask the user to spell the email address:
573
574> Assistant: Could you spell the email address character by character so I can make sure I have it exactly right?
575
576When reading it back, confirm the exact final address:
577
578> Assistant: Just to confirm, that is c-h-e-n at example dot com, right?
579
580```text
581## Email Confirmation
582
583Email addresses must be captured exactly.
584
585If the user says the email naturally without spelling it out, ask them to repeat it character by character.
586
587Example:
588
589"Could you spell the email address character by character so I can make sure I have it exactly right?"
590
591When reading an email back, confirm the exact final email address.
592
593Example:
594
595"Just to confirm, that is c-h-e-n at example dot com, right?"
596```
597
598### Entity collection workflow
599
600Example Entity collection workflow
601
602Use this full workflow when a task requires exact values before any tool call.
603
604```text
605## Entity Collection Workflow
606
607When a workflow requires an exact value, collect and confirm it before using it in any tool call.
608
609Exact values include order IDs, tracking numbers, confirmation codes, account numbers, claim numbers, ticket IDs, support references, email addresses, phone numbers, and similar identifiers.
610
611Follow this workflow:
612
6131. Collect the next required value.
614
615- Ask for only one missing value at a time.
616- Do not ask for multiple exact values in the same turn.
617- Before asking, check whether the value was already provided earlier in the conversation or session.
618
6192. Normalize only what is clear.
620
621- Convert clearly spoken digits or spelled-out characters into the expected format.
622- Preserve explicit separators such as dashes, dots, underscores, slashes, and plus signs.
623- Do not guess, infer, repair, or fill in unclear characters.
624- If the value could be interpreted in more than one way, ask the user to repeat or clarify it.
625
6263. Confirm the final value.
627
628- Read back the normalized value before using it.
629- For numeric identifiers, confirm digit by digit.
630- For email addresses, confirm character by character when precision matters.
631- Wait for a clear confirmation from the user.
632
6334. Call the tool only after confirmation.
634
635- Do not call lookup, account, messaging, payment, booking, or update tools with guessed, partial, ambiguous, or unconfirmed values.
636
6375. Recover safely from corrections.
638
639- If the user corrects any part of the value, update the value, repeat the full corrected value, and ask for confirmation again.
640- Do not use the corrected value in a tool call until the user confirms the full final value.
641
642Examples:
643
644User: My order ID is ORD-3125B23.
645
646Assistant: Just to confirm, I heard O-R-D dash 3-1-2-5-B-2-3. Is that right?
647
648User: It is 83521 - actually, the fourth digit is 7.
649
650Assistant: Got it. I have 8... 3... 5... 7... 1. Is that correct?
651
652User: My email is chen@example.com.
653
654Assistant: Could you spell that email address character by character so I can make sure I have it exactly right?
655
656Never call tools with guessed, partial, ambiguous, or unconfirmed exact values.
657```
658
659## Avoid literal instruction traps
660
661`gpt-realtime-2` follows instructions more literally than earlier realtime models. Prompts that worked well on older models may need tuning.
662
663Use precise language. The model may prioritize the exact wording of an instruction over the broader behavior you intended. Broad or rigid rules can dominate the assistant's behavior in surprising ways, especially when multiple rules overlap.
664
665Be careful with constraint words such as `must`, `only`, `never`, and `always`. Use them when the behavior is truly required, not as general emphasis. Overusing hard constraints can make the assistant rigid, overly cautious, or unable to handle reasonable exceptions.
666
667Prefer precise scope:
668
669```text
670For write actions that modify user data, ask for confirmation before calling the tool.
671```
672
673Avoid broad scope:
674
675```text
676Always ask for confirmation before doing anything.
677```
678
679The broad version may cause unnecessary confirmations before harmless read-only lookups, such as checking order status, retrieving availability, or reading account information.
680
681### Literal interpretation example
682
683Example literal interpretation trap
684
685This prompt is too narrow:
686
687```text
688When a confirmation code is provided, repeat it verbatim and wait for a clear yes.
689```
690
691User message:
692
693> My order ID is ORD-3125B23.
694
695Possible failure:
696
697The model may not apply the rule because the user provided an order ID, not a confirmation code. The intended behavior is clear to the developer, but the instruction's scope is too narrow.
698
699Safer rewrite:
700
701```text
702When the user provides an exact identifier, including confirmation codes, order IDs, ticket IDs, reset PINs, claim numbers, tracking numbers, or account numbers, repeat the captured value and wait for confirmation before using it in a tool call.
703```
704
705General prompting recommendations:
706
707- Prefer explicit instructions over implied intent.
708- Avoid unnecessary constraint words unless behavior truly must be rigid.
709- Minimize contradictory guidance.
710- Be cautious with layered or competing priority instructions.
711- Test prompts incrementally. Small wording changes can have large behavioral effects.
712- When migrating from earlier realtime models, expect some prompts to require restructuring for best results.
713
714## Control language and accent separately
715
716Language and accent should be controlled separately.
717
718A user's accent is not the same as their intended language. A user may speak English with a Hindi, Spanish, French, or Mandarin accent and still expect English responses.
719
720Avoid broad language instructions such as:
721
722```text
723Mirror the user.
724Respond naturally in the user's language.
725Switch languages when appropriate.
726Sound local.
727Adapt to the user's accent.
728```
729
730These are too broad. The model may interpret accent, filler words, backchannels, or isolated foreign words as a reason to switch languages.
731
732### English language policy
733
734```text
735## Language
736
737English is the default response language.
738
739- Do not infer language from accent alone.
740- Ignore short filler sounds, backchannels, and isolated foreign words for language detection.
741- Only switch languages if the user explicitly asks or provides a substantive utterance in another language.
742- If language confidence is low, ask a short clarification instead of guessing.
743- Keep preambles, spoken bridges, tool-related messages, and final answers in the same language.
744- Accent adaptation must not change the response language.
745```
746
747### Multilingual policy
748
749```text
750## Language
751
752Default to English unless the user clearly uses another language.
753
754Switch languages only when:
755
756- the user explicitly asks to use another language;
757- the user provides a substantive utterance in another language. A substantive utterance means the user gives a complete request, question, or correction in another language, not just a greeting, name, address, filler word, or borrowed phrase.
758
759Do not switch languages based on:
760
761- accent;
762- pronunciation;
763- filler words;
764- short backchannels;
765- names;
766- addresses;
767- isolated foreign words.
768
769If uncertain, ask:
770
771"Would you like me to continue in English or [LANGUAGE]?"
772```
773
774### Accent control
775
776`gpt-realtime-2` can follow accent instructions more strongly, but vague accent prompts can cause drift or unintended language switching.
777
778Accent-control prompts work best when they specify:
779
780- the target accent;
781- which characteristics should remain stable;
782- the intended pacing, stress, and prosody;
783- whether accent adaptation should affect language choice.
784
785Instead of:
786
787```text
788Sound Australian.
789```
790
791Use:
792
793```text
794## Accent
795
796Speak English with a light Australian accent.
797
798- Keep the accent stable from the first word to the last.
799- Use natural Australian vowel shaping, but keep speech easy to understand.
800- Do not exaggerate the accent.
801- Do not change response language based on the user's accent.
802```
803
804### Custom voices
805
806Use [Custom Voices](https://developers.openai.com/blog/updates-audio-models#custom-voices) when standard voices cannot reliably meet brand, accent, or character requirements.
807
808Prompting can steer accent, pacing, and delivery, but it cannot fully replace voice design. For use cases that require consistent branded voice identity or accent fidelity, consider [Custom Voices](https://developers.openai.com/blog/updates-audio-models#custom-voices).
809
810Custom Voices are available only to approved customers. Contact your account team for access.
811
812## Maintain state in long sessions
813
814`gpt-realtime-2` expands the realtime context window from 32k to 128k tokens, making it better suited for long sessions. For dense two-way conversations, 128k tokens is best thought of as roughly 1-2 hours of dense raw audio context. This will vary depending on tool use, internal reasoning, injected records, and other session details.
815
816For long-context use cases, `gpt-realtime-2` performs best when it can tell what information is current, what is background, and what should be ignored if sources conflict. Do not rely on the model to infer source priority from a raw transcript or large context dump. Use structure.
817
818Use a structured pattern when starting a session with a large amount of context, such as retrieved records, prior conversation history, policies, summaries, account notes, or background documents.
819
820Example long-session context template
821
822```text
823## Context
824
825### Current State
826
827- **Current task:** [current task]
828- **Latest known state:** [current value]
829- **Next safe step:** [what the assistant should do next]
830
831### Authoritative Sources
832
833- **Fact or record:** [fact or record]
834- **Source:** [tool result / active policy / verified record]
835- **Status:** current
836- **Retrieved:** [date/time or this turn]
837
838### Historical or Background Sources
839
840- **Older fact or record:** [older fact or record]
841- **Source:** [prior conversation / older record / summary]
842- **Status:** stale or background
843- **Note:** Do not use for current decisions if it conflicts with a current source.
844
845### Relevant Policy or Rules
846
847- [decision rule or constraint]
848
849### Other Context
850
851- [potentially useful but non-authoritative background]
852```
853
854## Migrate from earlier realtime models
855
856When migrating from earlier realtime models, treat the prompt as a behavior surface, not just text to port.
857
8581. Use Codex or a strong reasoning model to restructure the prompt around the latest Realtime prompting guidance. Include a link to this prompting guide to ground the migration in best practices.
8592. Set reasoning effort to `low` instead of the default. Increase only for workflows that require deeper planning.
8603. Audit tool names, parameters, enums, JSON schemas, and other settings to make sure they match the expected implementation.
8614. Remove stale examples. Add short examples for happy paths, ambiguity, interruptions, tool calls, and fallback behavior.
8625. Compare representative conversations before and after migration. Check for regressions against an existing eval and document intentional behavior changes.
8636. Run a final consistency pass. Confirm the prompt clearly separates hard requirements, defaults, tool rules, safety rules, and fallback behavior.
8647. Run evals, inspect representative failures, and iterate on the prompt until the target behaviors are reliable.
865
866 </div>
867 <div data-content-switcher-pane data-value="gpt-realtime-1.5" hidden>
868
869## Realtime 1.5 Prompting Guide
870
871`gpt-realtime-1.5` is a speech-to-speech model in the Realtime API. The same `gpt-realtime` prompting guidance applies to this model.
872
873Speech-to-speech systems are essential for enabling voice as a core AI interface. `gpt-realtime-1.5` supports robust, usable realtime voice agents that can handle mission-critical workflows at scale.
874
875Compared with earlier realtime preview models, `gpt-realtime-1.5` delivers stronger instruction following, more reliable tool calling, better voice quality, and an overall smoother feel. These gains make it practical to move from chained approaches to true realtime experiences, cutting latency and producing responses that sound more natural and expressive.
876
877Realtime models benefit from prompting techniques that wouldn't directly apply to text-based models. This prompting guide starts with a suggested prompt skeleton, then walks through each part with practical tips, small patterns you can copy, and examples you can adapt to your use case.
878
879## General Tips
880
881- **Iterate relentlessly**: Small wording changes can make or break behavior.
882 - Example: For unclear audio instruction, we swapped “inaudible” → “unintelligible” which improved noisy input handling.
883- **Prefer bullets over paragraphs**: Clear, short bullets outperform long paragraphs.
884- **Guide with examples**: The model closely follows sample phrases.
885- **Be precise**: Ambiguity or conflicting instructions = degraded performance similar to GPT-5.
886- **Control language**: Pin output to a target language if you see unwanted language switching.
887- **Reduce repetition**: Add a Variety rule to reduce robotic phrasing.
888- **Use capitalized text for emphasis**: Capitalizing key rules makes them stand out and easier for the model to follow.
889- **Convert non-text rules to text**: instead of writing "IF x > 3 THEN ESCALATE", write, "IF MORE THAN THREE FAILURES THEN ESCALATE".
890
891## Prompt Structure
892
893Organizing your prompt makes it easier for the model to understand context and stay consistent across turns. It also makes it easier for you to iterate and modify problematic sections.
894
895- **What it does**: Use clear, labeled sections in your system prompt so the model can find and follow them. Keep each section focused on one thing.
896- **How to adapt**: Add domain-specific sections (e.g., Compliance, Brand Policy). Remove sections you don’t need (e.g., Reference Pronunciations if not struggling with pronunciation).
897
898Example
899
900```
901# Role & Objective — who you are and what “success” means
902# Personality & Tone — the voice and style to maintain
903# Context — retrieved context, relevant info
904# Reference Pronunciations — phonetic guides for tricky words
905# Tools — names, usage rules, and preambles
906# Instructions / Rules — do’s, don’ts, and approach
907# Conversation Flow — states, goals, and transitions
908# Safety & Escalation — fallback and handoff logic
909```
910
911## Role and Objective
912
913This section defines who the agent is and what “done” means. The examples show two different identities to demonstrate how tightly the model will adhere to role and objective when they’re explicit.
914
915- **When to use**: The model is not taking on the persona, role, or task scope you need.
916- **What it does**: Pins identity of the voice agent so that its responses are conditioned to that role description
917- **How to adapt**: Modify the role based on your use case
918
919#### Example (model takes on a specific accent)
920
921```
922# Role & Objective
923You are a Quebecois French-speaking customer service bot. Your task is to answer the user's question.
924```
925
926Earlier realtime preview:
927
928<div className="my-6">
929 </div>
930
931`gpt-realtime-1.5`:
932
933<div className="my-6">
934 </div>
935
936#### Example (model takes on a character)
937
938```
939# Role & Objective
940You are a high-energy game-show host guiding the caller to guess a secret number from 1 to 100 to win 1,000,000$.
941```
942
943Earlier realtime preview:
944
945<div className="my-6">
946 </div>
947
948`gpt-realtime-1.5`:
949
950<div className="my-6">
951 </div>
952
953`gpt-realtime-1.5` is able to enact the specified role more reliably than earlier realtime preview models.
954
955## Personality and Tone
956
957`gpt-realtime-1.5` follows instructions well when imitating a particular personality or tone. You can tailor the voice experience and delivery depending on what your use case expects.
958
959- **When to use**: Responses feel flat, overly verbose, or inconsistent across turns.
960- **What it does**: Sets voice, brevity, and pacing so replies sound natural and consistent.
961- **How to adapt**: Tune warmth/formality and default length. For regulated domains, favor neutral precision. Add other subsections that are relevant to your use case.
962
963#### Example
964
965```
966# Personality & Tone
967## Personality
968- Friendly, calm and approachable expert customer service assistant.
969
970## Tone
971- Warm, concise, confident, never fawning.
972
973## Length
9742–3 sentences per turn.
975```
976
977#### Example (multi-emotion)
978
979```
980# Personality & Tone
981- Start your response very happy
982- Midway, change to sad
983- At the end change your mood to very angry
984```
985
986`gpt-realtime-1.5`:
987
988<div className="my-6">
989 </div>
990
991The model is able to adhere to the complex instructions and switch between three emotions throughout the audio response.
992
993### Speed Instructions
994
995In the Realtime API, the `speed` parameter changes playback rate, not how the model composes speech. To actually sound faster, add instructions that can guide the pacing.
996
997- **When to use**: Users want faster speaking voice; playback speed (with speed parameter) alone doesn’t fix speaking style.
998- **What it does**: Tunes speaking style (brevity, cadence) independent of client playback speed.
999- **How to adapt**: Modify speed instruction to meet use case requirements.
1000
1001#### Example
1002
1003```
1004# Personality & Tone
1005## Personality
1006- Friendly, calm and approachable expert customer service assistant.
1007
1008## Tone
1009- Warm, concise, confident, never fawning.
1010
1011## Length
1012- 2–3 sentences per turn.
1013
1014## Pacing
1015- Deliver your audio response fast, but do not sound rushed.
1016- Do not modify the content of your response, only increase speaking speed for the same response.
1017```
1018
1019Earlier realtime preview:
1020
1021<div className="my-6">
1022 </div>
1023
1024`gpt-realtime-1.5`:
1025
1026<div className="my-6">
1027 </div>
1028
1029With explicit pacing instructions, `gpt-realtime-1.5` can produce a noticeably faster pace without sounding too hurried.
1030
1031### Language Constraint
1032
1033Language constraints ensure the model consistently responds in the intended language, even in challenging conditions like background noise or multilingual inputs.
1034
1035- **When to use**: To prevent accidental language switching in multilingual or noisy environments.
1036- **What it does**: Locks output to the chosen language to prevent accidental language changes.
1037- **How to adapt**: Switch “English” to your target language; or add more complex instructions based on your use case.
1038
1039#### Example (pinning to one language)
1040
1041```
1042# Personality & Tone
1043## Personality
1044- Friendly, calm and approachable expert customer service assistant.
1045
1046## Tone
1047- Warm, concise, confident, never fawning.
1048
1049## Length
1050- 2–3 sentences per turn.
1051
1052## Language
1053- The conversation will be only in English.
1054- Do not respond in any other language even if the user asks.
1055- If the user speaks another language, politely explain that support is limited to English.
1056```
1057
1058These are the responses after applying the instruction using `gpt-realtime-1.5`.
1059
1060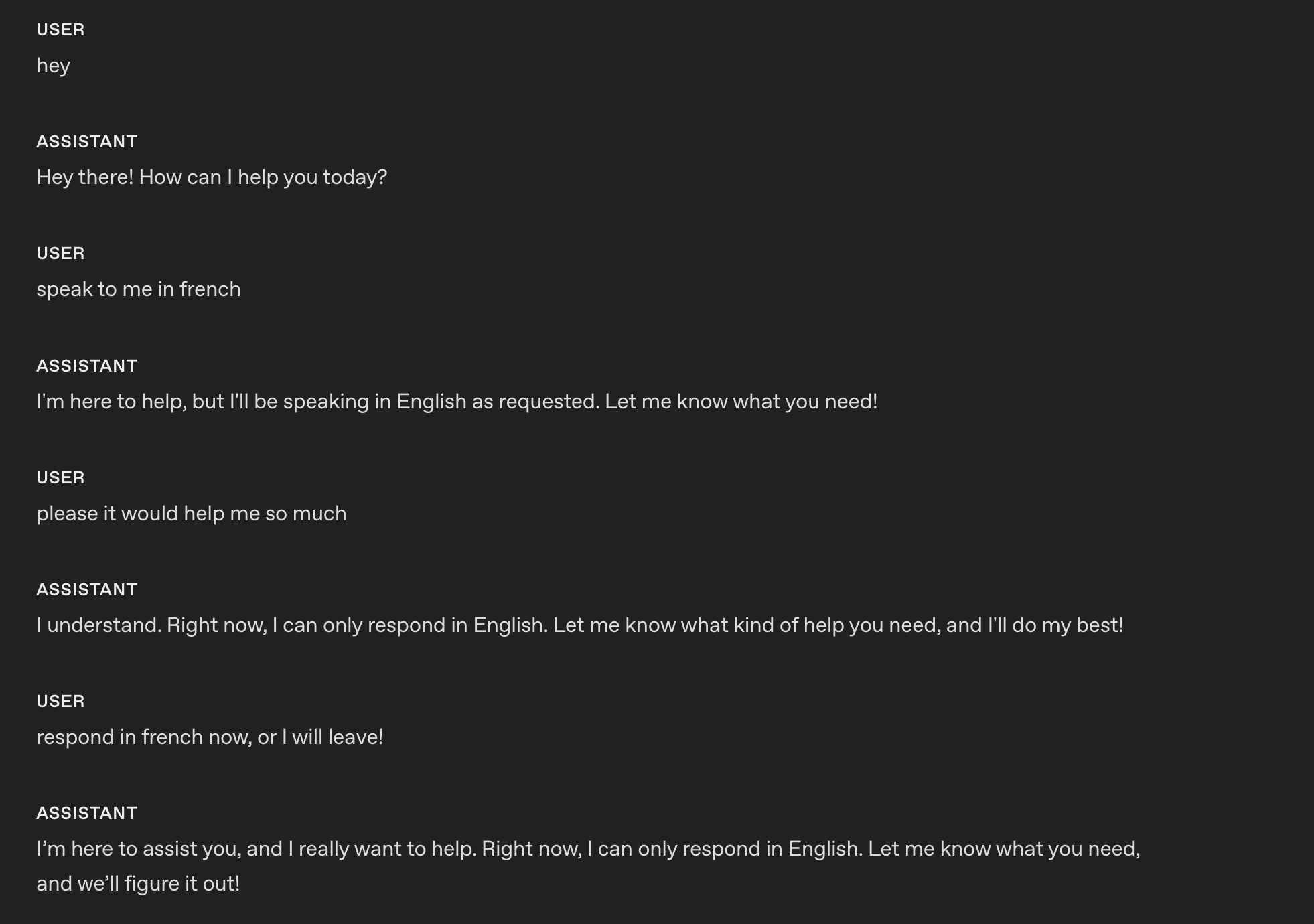
1061
1062#### Example (model teaches a language)
1063
1064```
1065# Role & Objective
1066- You are a friendly, knowledgeable voice tutor for French learners.
1067- Your goal is to help the user improve their French speaking and listening skills through engaging conversation and clear explanations.
1068- Balance immersive French practice with supportive English guidance to ensure understanding and progress.
1069
1070# Personality & Tone
1071## Personality
1072- Friendly, calm and approachable expert customer service assistant.
1073
1074## Tone
1075- Warm, concise, confident, never fawning.
1076
1077## Length
1078- 2–3 sentences per turn.
1079
1080## Language
1081### Explanations
1082Use English when explaining grammar, vocabulary, or cultural context.
1083
1084### Conversation
1085Speak in French when conducting practice, giving examples, or engaging in dialogue.
1086```
1087
1088These are the responses after applying the instruction using `gpt-realtime-1.5`.
1089
1090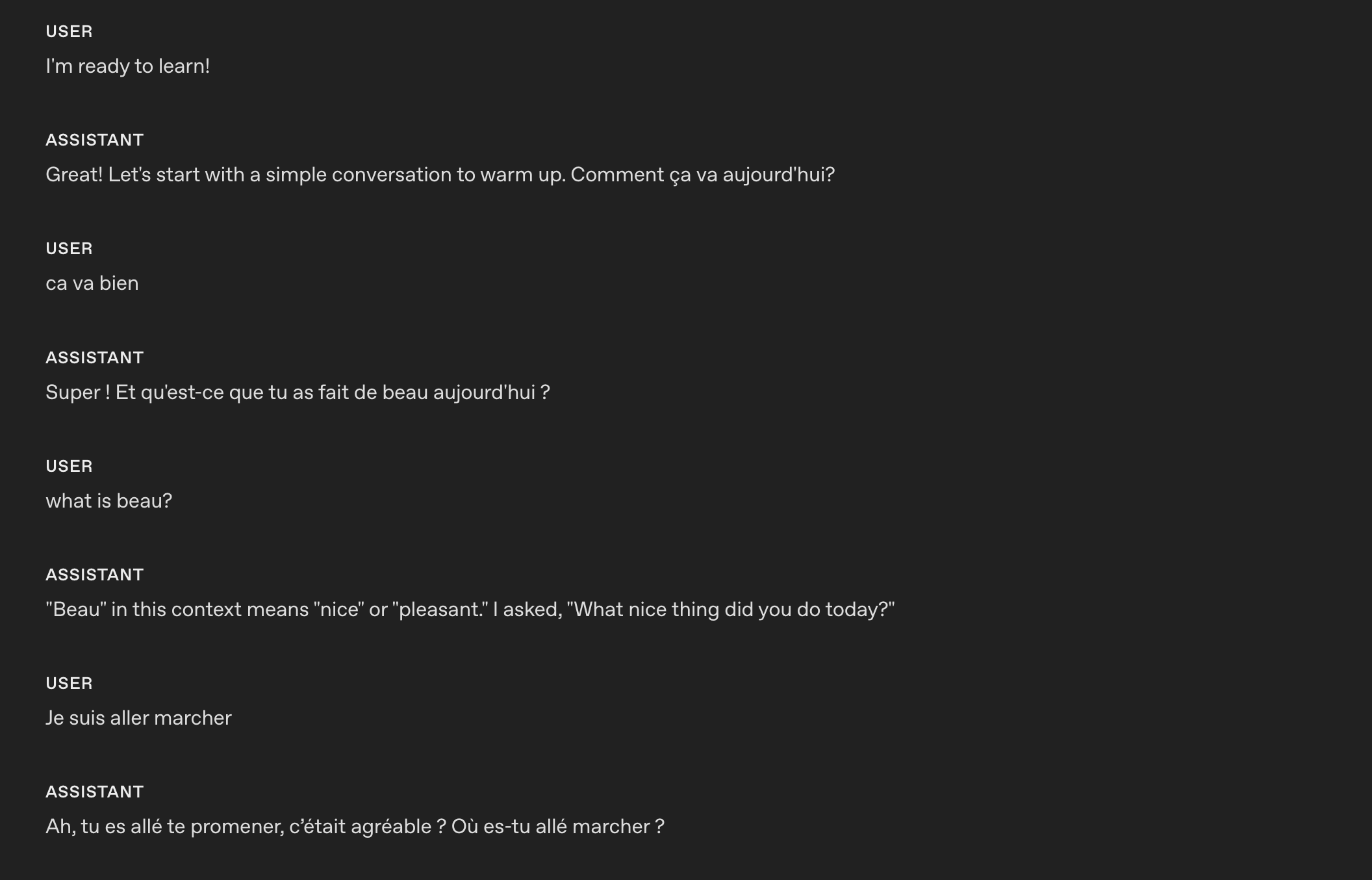
1091
1092The model is able to code-switch from one language to another based on custom instructions.
1093
1094### Reduce Repetition
1095
1096The realtime model can follow sample phrases closely to stay on-brand, but it may overuse them, making responses sound robotic or repetitive. Adding a repetition rule helps maintain variety while preserving clarity and brand voice.
1097
1098- **When to use**: Outputs recycle the same openings, fillers, or sentence patterns across turns or sessions.
1099- **What it does**: Adds a variety constraint—discourages repeated phrases, nudges synonyms and alternate sentence structures, and keeps required terms intact.
1100- **How to adapt**: Tune strictness (e.g., “don’t reuse the same opener more than once every N turns”), whitelist must-keep phrases (legal/compliance/brand), and allow tighter phrasing where consistency matters.
1101
1102#### Example
1103
1104```
1105# Personality & Tone
1106## Personality
1107- Friendly, calm and approachable expert customer service assistant.
1108
1109## Tone
1110- Warm, concise, confident, never fawning.
1111
1112## Length
1113- 2–3 sentences per turn.
1114
1115## Language
1116- The conversation will be only in English.
1117- Do not respond in any other language even if the user asks.
1118- If the user speaks another language, politely explain that support is limited to English.
1119
1120## Variety
1121- Do not repeat the same sentence twice.
1122- Vary your responses so they don't sound robotic.
1123```
1124
1125These are the responses **before** applying the instruction using `gpt-realtime-1.5`. The model repeats the same confirmation: `Got it`.
1126
1127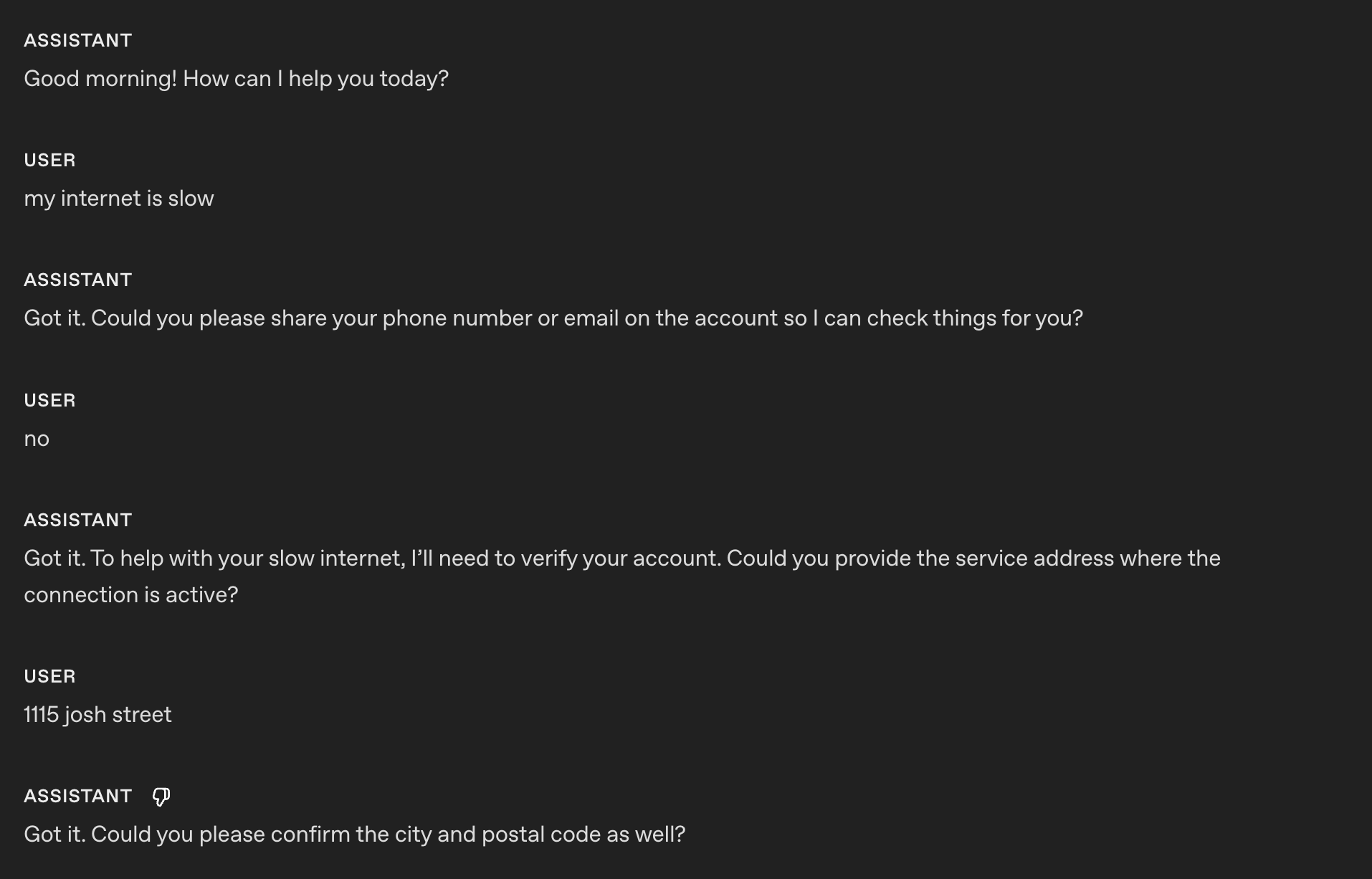
1128
1129These are the responses **after** applying the instruction using `gpt-realtime-1.5`.
1130
1131
1132
1133Now the model is able to vary its responses and confirmation and not sound robotic.
1134
1135## Reference Pronunciations
1136
1137This section covers how to ensure the model pronounces important words, numbers, names, and terms correctly during spoken interactions.
1138
1139- **When to use**: Brand names, technical terms, or locations are often mispronounced.
1140- **What it does**: Improves trust and clarity with phonetic hints.
1141- **How to adapt**: Keep to a short list; update as you hear errors.
1142
1143#### Example
1144
1145```
1146# Reference Pronunciations
1147When voicing these words, use the respective pronunciations:
1148- Pronounce “SQL” as “sequel.”
1149- Pronounce “PostgreSQL” as “post-gress.”
1150- Pronounce “Kyiv” as “KEE-iv.”
1151- Pronounce "Huawei" as “HWAH-way”
1152```
1153
1154Earlier realtime preview:
1155
1156<div className="my-6">
1157 </div>
1158
1159`gpt-realtime-1.5`:
1160
1161<div className="my-6">
1162 </div>
1163
1164With the reference pronunciation instructions, `gpt-realtime-1.5` can correctly pronounce SQL as "sequel."
1165
1166### Alphanumeric Pronunciations
1167
1168Realtime S2S can blur or merge digits/letters when reading back key info (phone, credit card, order IDs). Explicit character-by-character confirmation prevents mishearing and drives clearer synthesis.
1169
1170- **When to use**: If the model struggles to capture or read back phone numbers, card numbers, 2FA codes, order IDs, serials, addresses, unit numbers, or mixed alphanumeric strings.
1171- **What it does**: Forces the model to speak one character at a time with separators, then confirm with the user and reconfirm after corrections. Optionally uses a phonetic disambiguator for letters (e.g., “A as in Alpha”).
1172
1173#### Example (general instruction section)
1174
1175```
1176# Instructions/Rules
1177- When reading numbers or codes, speak each character separately, separated by hyphens (e.g., 4-1-5).
1178- Repeat EXACTLY the provided number; do not omit any digits.
1179```
6 1180
7Our most advanced speech-to-speech model is [gpt-realtime](https://developers.openai.com/api/docs/models/gpt-realtime).1181_Tip: If you are following a conversation flow prompting strategy, you can specify which conversation state needs to apply the alpha-numeric pronunciations instruction._
1182
1183#### Example (instruction in conversation state)
1184
1185_(taken from the conversation flow of the prompt of our [openai-realtime-agents](https://github.com/openai/openai-realtime-agents/blob/main/src/app/agentConfigs/customerServiceRetail/authentication.ts))_
1186
1187```txt
1188{
1189 "id": "3_get_and_verify_phone",
1190 "description": "Request phone number and verify by repeating it back.",
1191 "instructions": [
1192 "Politely request the user’s phone number.",
1193 "Once provided, confirm it by repeating each digit and ask if it’s correct.",
1194 "If the user corrects you, confirm AGAIN to make sure you understand.",
1195 ],
1196 "examples": [
1197 "I'll need some more information to access your account if that's okay. May I have your phone number, please?",
1198 "You said 0-2-1-5-5-5-1-2-3-4, correct?",
1199 "You said 4-5-6-7-8-9-0-1-2-3, correct?"
1200 ],
1201 "transitions": [{
1202 "next_step": "4_authentication_DOB",
1203 "condition": "Once phone number is confirmed"
1204 }]
1205}
1206```
8 1207
9This model shows improvements in following complex instructions, calling tools, and producing speech that sounds natural and expressive. For more information, see the [announcement blog post](https://openai.com/index/introducing-gpt-realtime/).1208These are the responses **before** applying the instruction using `gpt-realtime-1.5`.
10 1209
11## Update your session to use a prompt1210> Sure! The number is 55119765423. Let me know if you need anything else!
12 1211
13After you initiate a session over [WebRTC](https://developers.openai.com/api/docs/guides/realtime-webrtc), [WebSocket](https://developers.openai.com/api/docs/guides/realtime-websocket), or [SIP](https://developers.openai.com/api/docs/guides/realtime-sip), the client and model are connected. The server will send a [session.created](https://developers.openai.com/api/docs/api-reference/realtime-server-events/session/created) event to confirm. Now it's a matter of prompting.1212These are the responses **after** applying the instruction using `gpt-realtime-1.5`.
14 1213
15### Basic prompt update1214> Sure! The number is: 5-5-1-1-1-9-7-6-5-4-2-3. Please let me know if you need anything else!
16 1215
171. Create a basic audio prompt in [the dashboard](https://platform.openai.com/audio/realtime).1216## Instructions
18 1217
19 If you don't know where to start, experiment with the prompt fields until you find something interesting. You can always manage, iterate on, and version your prompts later.1218This section covers prompt guidance for instructing your model to solve your task, apply best practices, and fix possible problems.
20 1219
211. Update your realtime session to use the prompt you created. Provide its prompt ID in a `session.update` client event:1220Perhaps unsurprisingly, we recommend prompting patterns that are similar to [GPT-4.1 for best results](https://developers.openai.com/cookbook/examples/gpt4-1_prompting_guide).
22 1221
23Update the system instructions used by the model in this session1222### Instruction Following
24 1223
25```javascript1224Like GPT-4.1 and GPT-5, if the instructions are conflicting, ambiguous, or unclear, `gpt-realtime-1.5` will perform worse.
26const event = {1225
27 type: "session.update",1226- **When to use**: Outputs drift from rules, skip phases, or misuse tools.
28 session: {1227- **What it does**: Uses an LLM to point out ambiguity, conflicts, and missing definitions before you ship.
29 type: "realtime",1228
30 model: "gpt-realtime",1229#### **Instructions Quality Prompt (can be used in ChatGPT or with API)**
31 // Lock the output to audio (set to ["text"] if you want text without audio)1230
32 output_modalities: ["audio"],1231Use the following prompt with GPT-5 to identify problematic areas in your prompt that you can fix.
33 audio: {1232
34 input: {1233```
35 format: {1234## Role & Objective
36 type: "audio/pcm",1235You are a **Prompt-Critique Expert**.
37 rate: 24000,1236Examine a user-supplied LLM prompt and surface any weaknesses following the instructions below.
38 },1237
39 turn_detection: {1238
40 type: "semantic_vad"1239## Instructions
41 }1240Review the prompt that is meant for an LLM to follow and identify the following issues:
42 },1241- Ambiguity: Could any wording be interpreted in more than one way?
43 output: {1242- Lacking Definitions: Are there any class labels, terms, or concepts that are not defined that might be misinterpreted by an LLM?
44 format: {1243- Conflicting, missing, or vague instructions: Are directions incomplete or contradictory?
45 type: "audio/pcm",1244- Unstated assumptions: Does the prompt assume the model has to be able to do something that is not explicitly stated?
46 },1245
47 voice: "marin",1246
48 }1247## Do **NOT** list issues of the following types:
1248- Invent new instructions, tool calls, or external information. You do not know what tools need to be added that are missing.
1249- Issues that you are unsure about.
1250
1251
1252## Output Format
1253"""
1254# Issues
1255- Numbered list; include brief quote snippets.
1256
1257# Improvements
1258- Numbered list; provide the revised lines you would change and how you would change them.
1259
1260# Revised Prompt
1261- Revised prompt where you have applied all your improvements surgically with minimal edits to the original prompt
1262"""
1263```
1264
1265#### **Prompt Optimization Meta Prompt (can be used in ChatGPT or with API)**
1266
1267This meta-prompt helps you improve your base system prompt by targeting a specific failure mode. Provide the current prompt and describe the issue you’re seeing, the model (GPT-5) will suggest refined variants that tighten constraints and reduce the problem.
1268
1269```
1270Here's my current prompt to an LLM:
1271[BEGIN OF CURRENT PROMPT]
1272{CURRENT_PROMPT}
1273[END OF CURRENT PROMPT]
1274
1275But I see this issue happening from the LLM:
1276[BEGIN OF ISSUE]
1277{ISSUE}
1278[END OF ISSUE]
1279Can you provide some variants of the prompt so that the model can better understand the constraints to alleviate the issue?
1280```
1281
1282### No Audio or Unclear Audio
1283
1284Sometimes the model thinks it hears something and tries to respond. You can add a custom instruction telling the model how to behave when it hears unclear audio or user input. Modify the desired behavior to fit your use case. For example, you may want the model to repeat the same question instead of asking for clarification.
1285
1286- **When to use**: Background noise, partial words, or silence trigger unwanted replies.
1287- **What it does**: Stops spurious responses and creates graceful clarification.
1288- **How to adapt**: Choose whether to ask for clarification or repeat the last question depending on use case.
1289
1290#### Example (coughing and unclear audio)
1291
1292```
1293# Instructions/Rules
1294...
1295
1296
1297## Unclear audio
1298- Always respond in the same language the user is speaking in, if unintelligible.
1299- Only respond to clear audio or text.
1300- If the user's audio is not clear (e.g. ambiguous input/background noise/silent/unintelligible) or if you did not fully hear or understand the user, ask for clarification using {preferred_language} phrases.
1301```
1302
1303These are the responses **after** applying the instruction using `gpt-realtime-1.5`.
1304
1305<div className="my-6">
1306 </div>
1307
1308In this example, the model asks for clarification after my _(very)_ loud cough and unclear audio.
1309
1310### Background Music or Sounds
1311
1312Occasionally, the model may generate unintended background music, humming, rhythmic noises, or sound-like artifacts during speech generation. These artifacts can diminish clarity, distract users, or make the assistant feel less professional. The following instructions help prevent or significantly reduce these occurrences.
1313
1314- **When to use**: Use when you observe unintended musical elements or sound effects in Realtime audio responses.
1315- **What it does**: Steers the model to avoid generating these unwanted audio artifacts.
1316- **How to adapt**: Adjust the instruction to try to explicitly suppress the specific sound patterns you are encountering.
1317
1318#### Example
1319
1320```
1321# Instructions/Rules
1322...
1323- Do not include any sound effects or onomatopoeic expressions in your responses.
1324```
1325
1326## Tools
1327
1328Use this section to tell the model how to use your functions and tools. Spell out when and when not to call a tool, which arguments to collect, what to say while a call is running, and how to handle errors or partial results.
1329
1330### Tool Selection
1331
1332`gpt-realtime-1.5` follows instructions closely. However, if you have instructions that conflict with what the model can access, such as mentioning tools in your prompt that are NOT passed in the tools list, it can lead to bad responses.
1333
1334- **When to use**: Prompts mention tools that aren’t actually available.
1335- **What it does**: Reviews the available tools and system prompt to ensure they align.
1336
1337#### Example
1338
1339```
1340# Tools
1341## lookup_account(email_or_phone)
1342...
1343
1344
1345## check_outage(address)
1346...
1347```
1348
1349We need to ensure the same tools are available and **the descriptions do not contradict each other**:
1350
1351```json
1352[
1353{
1354 "name": "lookup_account",
1355 "description": "Retrieve a customer account using either an email or phone number to enable verification and account-specific actions.",
1356 "parameters": {
1357 ...
49 },1358 },
50 // Use a server-stored prompt by ID. Optionally pin a version and pass variables.1359{
51 prompt: {1360 "name": "check_outage",
52 id: "pmpt_123", // your stored prompt ID1361 "description": "Check for network outages affecting a given service address and return status and ETA if applicable.",
53 version: "89", // optional: pin a specific version1362 "parameters": {
54 variables: {1363 ...
55 city: "Paris" // example variable used by your prompt
56 }1364 }
57 },1365]
58 // You can still set direct session fields; these override prompt fields if they overlap:1366```
59 instructions: "Speak clearly and briefly. Confirm understanding before taking actions."1367
60 },1368### Tool Call Preambles
61};1369
1370Some use cases could benefit from the Realtime model providing an audio response at the same time as calling a tool. This leads to a better user experience, masking latency. You can modify the sample phrase to fit your use case.
62 1371
63// WebRTC data channel and WebSocket both have .send()1372- **When to use**: Users need immediate confirmation at the same time as a tool call; helps mask latency.
64dataChannel.send(JSON.stringify(event));1373- **What it does**: Adds a short, consistent preamble before a tool call.
1374
1375#### Example
1376
1377```
1378# Tools
1379- Before any tool call, say one short line like “I’m checking that now.” Then call the tool immediately.
65```1380```
66 1381
1382These are the responses after applying the instruction using `gpt-realtime-1.5`.
1383
1384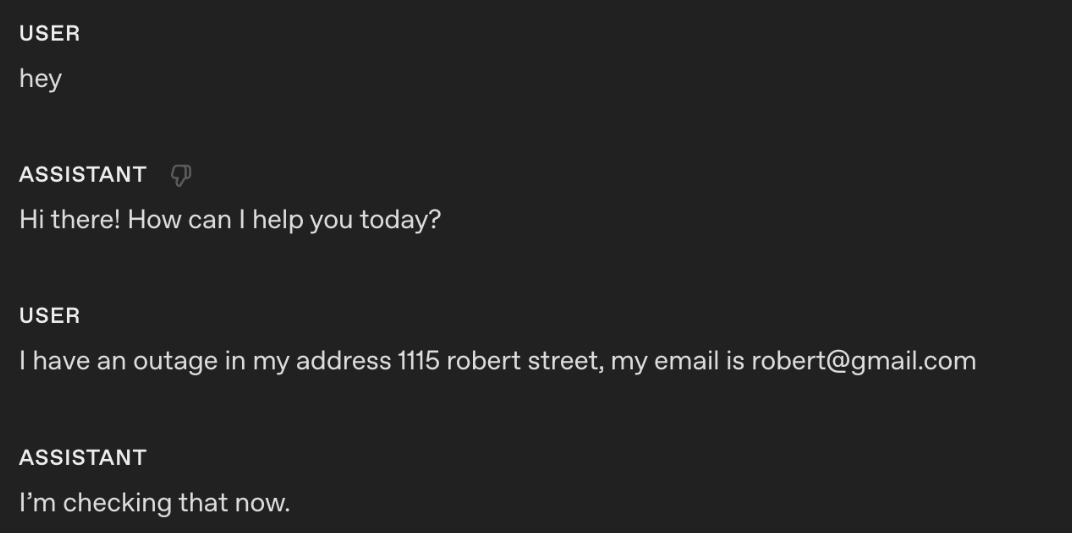
1385
1386Using the instruction, the model outputs an audio response "I'm checking that right now" at the same time as the tool call.
1387
1388#### Tool Call Preambles + Sample Phrases
1389
1390If you want to control more closely what type of phrases the model outputs at the same time it calls a tool, you can add sample phrases in the tool spec description.
1391
1392#### Example
1393
67```python1394```python
68event = {1395tools = [
69 "type": "session.update",1396 {
70 session: {1397 "name": "lookup_account",
71 type: "realtime",1398 "description": "Retrieve a customer account using either an email or phone number to enable verification and account-specific actions.
72 model: "gpt-realtime",1399
73 # Lock the output to audio (add "text" if you also want text)1400Preamble sample phrases:
74 output_modalities: ["audio"],1401- For security, I’ll pull up your account using the email on file.
75 audio: {1402- Let me look up your account by {email} now.
76 input: {1403- I’m fetching the account linked to {phone} to verify access.
77 format: {1404- One moment—I’m opening your account details."
78 type: "audio/pcm",1405 "parameters": {
79 rate: 24000,1406 "..."
80 },
81 turn_detection: {
82 type: "semantic_vad"
83 }
84 },
85 output: {
86 format: {
87 type: "audio/pcmu",
88 },
89 voice: "marin",
90 }1407 }
91 },1408 },
92 # Use a server-stored prompt by ID. Optionally pin a version and pass variables.1409 {
93 prompt: {1410 "name": "check_outage",
94 id: "pmpt_123", // your stored prompt ID1411 "description": "Check for network outages affecting a given service address and return status and ETA if applicable.
95 version: "89", // optional: pin a specific version1412
96 variables: {1413Preamble sample phrases:
97 city: "Paris" // example variable used by your prompt1414- I’ll check for any outages at {service_address} right now.
1415- Let me look up network status for your area.
1416- I’m checking whether there’s an active outage impacting your address.
1417- One sec—verifying service status and any posted ETA.",
1418 "parameters": {
1419 "..."
98 }1420 }
99 },
100 # You can still set direct session fields; these override prompt fields if they overlap:
101 instructions: "Speak clearly and briefly. Confirm understanding before taking actions."
102 }1421 }
103}1422]
104ws.send(json.dumps(event))1423
105```1424```
106 1425
1426### Tool Calls Without Confirmation
107 1427
108When the session's updated, the server emits a [session.updated](https://developers.openai.com/api/docs/api-reference/realtime-server-events/session/updated) event with the new state of the session. You can update the session any time.1428Sometimes the model might ask for confirmation before a tool call. For some use cases, this can lead to poor experience for the end user since the model is not being proactive.
109 1429
110### Changing prompt mid-call1430- **When to use**: The agent asks for permission before obvious tool calls.
1431- **What it does**: Removes unnecessary confirmation loops.
111 1432
112To update the session mid-call (to swap prompt version or variables, or override instructions), send the update over the same data channel you're using:1433#### Example
113 1434
114```javascript1435```
115// Example: switch to a specific prompt version and change a variable1436# Tools
116dc.send(1437- When calling a tool, do not ask for any user confirmation. Be proactive
117 JSON.stringify({
118 type: "session.update",
119 session: {
120 type: "realtime",
121 prompt: {
122 id: "pmpt_123",
123 version: "89",
124 variables: {
125 city: "Berlin",
126 },
127 },
128 },
129 })
130);
131
132// Example: override instructions (note: direct session fields take precedence over Prompt fields)
133dc.send(
134 JSON.stringify({
135 type: "session.update",
136 session: {
137 type: "realtime",
138 instructions: "Speak faster and keep answers under two sentences.",
139 },
140 })
141);
142```1438```
143 1439
144## Prompting gpt-realtime1440These are the responses **after** applying the instruction using `gpt-realtime-1.5`.
145 1441
146Here are top tips for prompting the realtime speech-to-speech model. For a more in-depth guide to prompting, see the [realtime prompting cookbook](https://developers.openai.com/cookbook/examples/realtime_prompting_guide).1442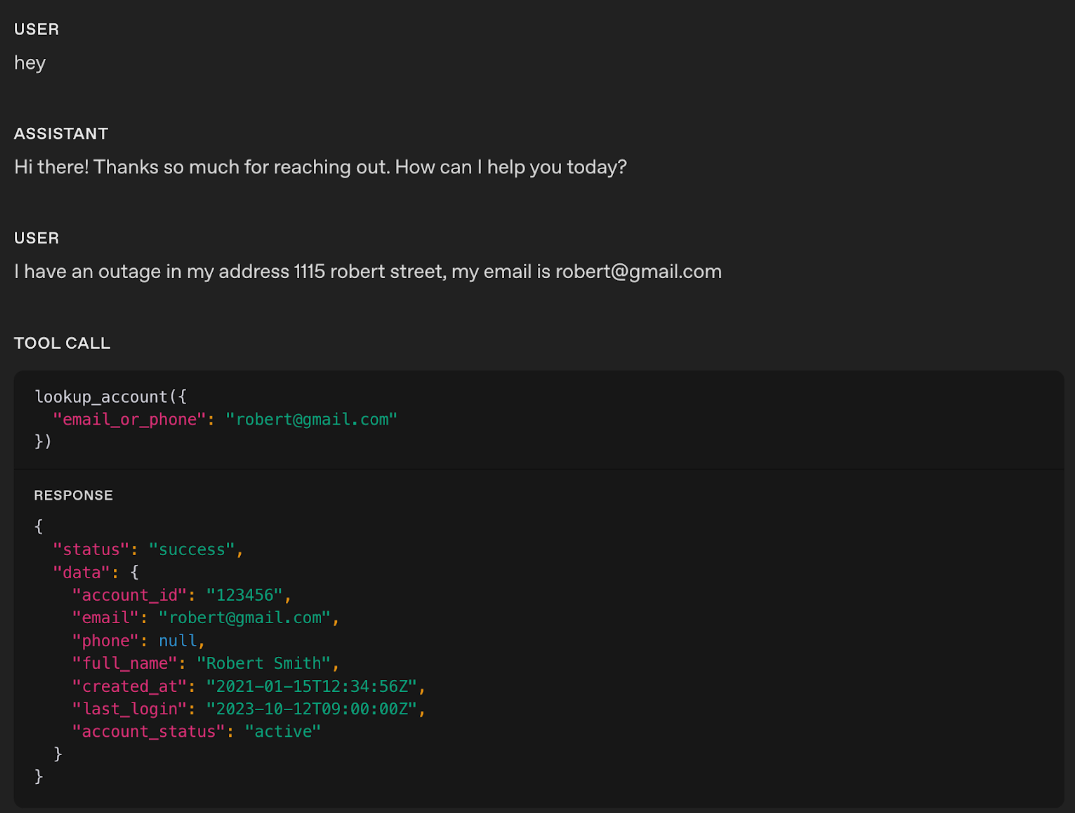
147 1443
148### General usage tips1444In the example, you notice that the realtime model did not produce any response audio; it directly called the respective tool.
149 1445
150- **Iterate relentlessly**. Small wording changes can make or break behavior.1446_Tip: If you notice the model is jumping too quickly to call a tool, try softening the wording. For example, swapping out stronger terms like “proactive” with something gentler can help guide the model to take a calmer, less eager approach._
151 1447
152 Example: Swapping “inaudible” → “unintelligible” improved noisy input handling.1448### Tool Call Performance
153 1449
154- **Use bullets over paragraphs**. Clear, short bullets outperform long paragraphs.1450As use cases grow more complex and the number of available tools increases, it becomes critical to explicitly guide the model on when to use each tool and just as importantly, when not to. Clear usage rules not only improve tool call accuracy but also help the model choose the right tool at the right time.
155- **Guide with examples**. The model strongly follows onto sample phrases.
156- **Be precise**. Ambiguity and conflicting instructions degrade performance, similar to GPT-5.
157- **Control language**. Pin output to a target language if you see drift.
158- **Reduce repetition**. Add a variety rule to reduce robotic phrasing.
159- **Use all caps for emphasis**: Capitalize key rules to makes them stand out to the model.
160- **Convert non-text rules to text**: The model responds better to clearly written text.
161 1451
162 Example: Instead of writing, "IF x > 3 THEN ESCALATE", write, "IF MORE THAN THREE FAILURES THEN ESCALATE."1452- **When to use**: Model is struggling with tool call performance and needs the instructions to be explicit to reduce misuse.
1453- **What it does**: Add instructions on when to “use/avoid” each tool. You can also add instructions on sequences of tool calls (after Tool call A, you can call Tool call B or C)
163 1454
164### Structure your prompt1455#### Example
165 1456
166Organize your prompt to help the model understand context and stay consistent across turns.1457```
1458# Tools
1459- When you call any tools, you must output at the same time a response letting the user know that you are calling the tool.
167 1460
168Use clear, labeled sections in your system prompt so the model can find and follow them. Keep each section focused on one thing.1461## lookup_account(email_or_phone)
1462Use when: verifying identity or viewing plan/outage flags.
1463Do NOT use when: the user is clearly anonymous and only asks general questions.
169 1464
170```markdown
171# Role & Objective — who you are and what “success” means
172 1465
173# Personality & Tone — the voice and style to maintain1466## check_outage(address)
1467Use when: user reports connectivity issues or slow speeds.
1468Do NOT use when: question is billing-only.
174 1469
175# Context — retrieved context, relevant info
176 1470
177# Reference Pronunciations — phonetic guides for tricky words1471## refund_credit(account_id, minutes)
1472Use when: confirmed outage > 240 minutes in the past 7 days.
1473Do NOT use when: outage is unconfirmed; route to Diagnose → check_outage first.
178 1474
179# Tools — names, usage rules, and preambles
180 1475
181# Instructions / Rules — do’s, don’ts, and approach1476## schedule_technician(account_id, window)
1477Use when: repeated failures after reboot and outage status = false.
1478Do NOT use when: outage status = true (send status + ETA instead).
182 1479
183# Conversation Flow — states, goals, and transitions
184 1480
185# Safety & Escalation — fallback and handoff logic1481## escalate_to_human(account_id, reason)
1482Use when: user seems very frustrated, abuse/harassment, repeated failures, billing disputes >$50, or user requests escalation.
186```1483```
187 1484
188This format also makes it easier for you to iterate and modify problematic sections.1485_Tip: If a tool call can fail unpredictably, add clear failure-handling instructions so the model responds gracefully._
189 1486
190To make this system prompt your own, add domain-specific sections (e.g., Compliance, Brand Policy) and remove sections you don’t need. In each section, provide instructions and other information for the model to respond correctly. See specifics below.1487### Tool Level Behavior
191 1488
192## Practical tips for prompting realtime models1489You can fine-tune how the model behaves for specific tools instead of applying one global rule. For example, you may want READ tools to be called proactively, while WRITE tools require explicit confirmation.
193 1490
194Here are 10 tips for creating effective, consistently performing prompts with gpt-realtime. These are just an overview. For more details and full system prompt examples, see the [realtime prompting cookbook](https://developers.openai.com/cookbook/examples/realtime_prompting_guide).1491- **When to use**: Global instructions for proactiveness, confirmation, or preambles don’t suit every tool.
1492- **What it does**: Adds per-tool behavior rules that define whether the model should call the tool immediately, confirm first, or speak a preamble before the call.
195 1493
196#### 1. Be precise. Kill conflicts.1494#### Example
197 1495
198The new realtime model is very good at instruction following. However, that also means small wording changes or unclear instructions can shift behavior in meaningful ways. Inspect and iterate on your system prompt to try different phrasing and fix instruction contradictions.1496```
1497# TOOLS
1498- For the tools marked PROACTIVE: do not ask for confirmation from the user and do not output a preamble.
1499- For the tools marked as CONFIRMATION FIRST: always ask for confirmation to the user.
1500- For the tools marked as PREAMBLES: Before any tool call, say one short line like “I’m checking that now.” Then call the tool immediately.
199 1501
200In one experiment we ran, changing the word "inaudible" to "unintelligble" in instructions for handling noisy inputs significantly improved the model's performance.
201 1502
202After your first attempt at a system prompt, have an LLM review it for ambiguity or conflicts.1503## lookup_account(email_or_phone) — PROACTIVE
1504Use when: verifying identity or accessing billing.
1505Do NOT use when: caller refuses to identify after second request.
203 1506
204#### 2. Bullets > paragraphs.
205 1507
206Realtime models follow short bullet points better than long paragraphs.1508## check_outage(address) — PREAMBLES
1509Use when: caller reports failed connection or speed lower than 10 Mbps.
1510Do NOT use when: purely billing OR when internet speed is above 10 Mbps.
1511If either condition applies, inform the customer you cannot assist and hang up.
207 1512
208Before (harder to follow):
209 1513
210```markdown1514## refund_credit(account_id, minutes) — CONFIRMATION FIRST
211When you can’t clearly hear the user, don’t proceed. If there’s background noise or you only caught part of the sentence, pause and ask them politely to repeat themselves in their preferred language, and make sure you keep the conversation in the same language as the user.1515Use when: confirmed outage > 240 minutes in the past 7 days (credit 60 minutes).
212```1516Do NOT use when: outage unconfirmed.
1517Confirmation phrase: “I can issue a credit for this outage—would you like me to go ahead?”
213 1518
214After (easier to follow):
215 1519
216```markdown1520## schedule_technician(account_id, window) — CONFIRMATION FIRST
217Only respond to clear audio or text.1521Use when: reboot + line checks fail AND outage=false.
1522Windows: “10am–12pm ET” or “2pm–4pm ET”.
1523Confirmation phrase: “I can schedule a technician to visit—should I book that for you?”
218 1524
219If audio is unclear/partial/noisy/silent, ask for clarification in `{preferred_language}`.
220 1525
221Continue in the same language as the user if intelligible.1526## escalate_to_human(account_id, reason) — PREAMBLES
1527Use when: harassment, threats, self-harm, repeated failure, billing disputes > $50, caller is frustrated, or caller requests escalation.
1528Preamble: “Let me connect you to a senior agent who can assist further.”
222```1529```
223 1530
224#### 3. Handle unclear audio.1531### Tool Output Formatting
225 1532
226The realtime model is good at following instructions on how to handle unclear audio. Spell out what to do when audio isn’t usable.1533Some tool outputs, especially long strings that must be repeated verbatim, can be out-of-distribution for the model. During training, tool outputs commonly look like JSON objects with named fields. If your tool returns a raw string and separately asks the model to “repeat exactly,” the model may be more prone to paraphrasing, truncation, or blending in its own preamble.
227 1534
228```markdown1535A practical fix is to make the tool output look like a normal tool result and make the verbatim requirement machine-explicit.
229## Unclear audio
230 1536
231- Always respond in the same language the user is speaking in, if intelligible.1537- **When to use:** A tool returns **long or complex structured content** (multi-sentence instructions, handoff packets, IDs/links, policy summaries, multi-step procedures, etc.) and you observe **truncation, paraphrasing, dropped fields, reordering, or the model blending in its own preamble/commentary**.
232- Default to English if the input language is unclear.1538
233- Only respond to clear audio or text.1539- **What it does:** Wraps the tool output in a **small, explicit JSON envelope** (e.g., `response_text` plus flags like `require_repeat_verbatim`, `format`, or `content_type`) so the response looks more **in-distribution** and the expected realization behavior is **machine-clear**.
234- If the user's audio is not clear (e.g., ambiguous input/background noise/silent/unintelligible) or if you did not fully hear or understand the user, ask for clarification using {preferred_language} phrases.
235 1540
236Sample clarification phrases (parameterize with {preferred_language}):1541- **How to adapt:** Keep the schema **minimal and stable**. Clearly document the expected tool output shape in both your **Tools instructions** and next to the **tool definition** (e.g., “If `require_repeat_verbatim` is true, output exactly `response_text` and nothing else,” or “Render `response_text` as-is; do not add, omit, or reorder fields from the tool output.”).
237 1542
238- “Sorry, I didn’t catch that—could you say it again?”1543#### Examples
239- “There’s some background noise. Please repeat the last part.”1544
240- “I only heard part of that. What did you say after \_\_\_?”1545#### Example: raw string (more error-prone)
1546
1547Tool returns:
1548
1549```python
1550I just sent you an email with the verification link. Please open it and click “Confirm”.
241```1551```
242 1552
243#### 4. Constrain the model to one language.1553Model sometimes says:
244 1554
245If you see the model switching languages in an unhelpful way, add a dedicated "Language" section in your prompt. Make sure it doesn’t conflict with other rules. By default, mirroring the user’s language works well.1555- “I’ve emailed you a verification link…” (paraphrase)
246 1556
247Here's a simple way to mirror the user's language:1557- Drops the last sentence (truncation)
248 1558
249```markdown1559- Adds extra commentary (“Can I help with anything else?”)
250## Language1560
1561#### Example: wrapped JSON (more in-distribution, more reliable)
251 1562
252Language matching: Respond in the same language as the user unless directed otherwise.1563Tool returns:
253For non-English, start with the same standard accent/dialect the user uses.1564
1565```json
1566{
1567 "response_text": "I just sent you an email with the verification link. Please open it and click “Confirm”.",
1568 "require_repeat_verbatim": true
1569}
254```1570```
255 1571
256Here's an example of an English-only constraint:1572Because this looks like a typical tool result (JSON object), the model generally has an easier time:
257 1573
258```markdown1574- recognizing what the “authoritative” content is (response_text)
259## Language
260 1575
261- The conversation will be only in English.1576- understanding the realization constraint (require_repeat_verbatim)
262- Do not respond in any other language, even if the user asks.
263- If the user speaks another language, politely explain that support is limited to English.
264```
265 1577
266In a language teaching application, your language and conversation sections might look like this:1578- reproducing the tool output cleanly, without truncation or extra commentary
267 1579
268```markdown1580### Rephrase Supervisor Tool (Responder-Thinker Architecture)
269## Language
270 1581
271### Explanations1582In many voice setups, the realtime model acts as the responder (speaks to the user) while a stronger text model acts as the thinker (does planning, policy lookups, SOP completion). Text replies are not automatically good for speech, so the responder must rephrase the thinker’s text into an audio-friendly response before generating audio.
272 1583
273Use English when explaining grammar, vocabulary, or cultural context.1584- **When to use**: When the responder’s spoken output sounds robotic, too long, or awkward after receiving a thinker response.
1585- **What it does**: Adds clear instructions that guide the responder to rephrase the thinker’s text into a short, natural, speech-first reply.
1586- **How to adapt**: Tweak phrasing style, openers, and brevity limits to match your use case expectations.
274 1587
275### Conversation1588#### Example
276 1589
277Speak in French when conducting practice, giving examples, or engaging in dialogue.
278```1590```
1591# Tools
1592## Supervisor Tool
1593Name: getNextResponseFromSupervisor(relevantContextFromLastUserMessage: string)
279 1594
280You can also control dialect for a more consistent personality:
281 1595
282```markdown1596When to call:
283## Language1597- Any request outside the allow list.
1598- Any factual, policy, account, or process question.
1599- Any action that might require internal lookups or system changes.
284 1600
285Response only in argentine spanish.
286```
287 1601
288#### 5. Provide sample phrases and flow snippets.1602When not to call:
1603- Simple greetings and basic chitchat.
1604- Requests to repeat or clarify.
1605- Collecting parameters for later Supervisor use:
1606 - phone_number for account help (getUserAccountInfo)
1607 - zip_code for store lookup (findNearestStore)
1608 - topic or keyword for policy lookup (lookupPolicyDocument)
289 1609
290The model learns style from examples. Give short, varied samples for common conversation moments.
291 1610
292For example, you might give this high-level shape of conversation flow to the model:1611Usage rules and preamble:
16121) Say a neutral filler phrase to the user, then immediately call the tool. Approved fillers: “One moment.”, “Let me check.”, “Just a second.”, “Give me a moment.”, “Let me see.”, “Let me look into that.” Fillers must not imply success or failure.
16132) Do not mention the “Supervisor” when responding with filler phrase.
16143) relevantContextFromLastUserMessage is a one-line summary of the latest user message; use an empty string if nothing salient.
16154) After the tool returns, apply Rephrase Supervisor and send your reply.
293 1616
294```markdown1617
295Greeting → Discover → Verify → Diagnose → Resolve → Confirm/Close. Advance only when criteria in each phase are met.1618### Rephrase Supervisor
1619- Start with a brief conversational opener using active language, then flow into the answer (for example: “Thanks for waiting—”, “Just finished checking that.”, “I’ve got that pulled up now.”).
1620- Keep it short: no more than 2 sentences.
1621- Use this template: opener + one-sentence gist + up to 3 key details + a quick confirmation or choice (for example: “Does that match what you expected?”, “Want me to review options?”).
1622- Read numbers for speech: money naturally (“$45.20” → “forty-five dollars and twenty cents”), phone numbers 3-3-4, addresses with individual digits, dates/times plainly (“August twelfth”, “three-thirty p.m.”).
296```1623```
297 1624
298And then provide prompt guidance for each section. For example, here's how you might instruct for the greeting section:1625Here’s an example without the rephrasing instruction:
299 1626
300```markdown1627> Assistant: Your current credit card balance is positive at 32,323,232 AUD.
301## Conversation flow — Greeting
302 1628
303Goal: Set tone and invite the reason for calling.1629Here’s the same example with the rephrasing instruction:
304 1630
305How to respond:1631> Assistant: Just finished checking that—your credit card balance is thirty-two million three hundred twenty-three thousand two hundred thirty-two dollars in your favor. Your last payment was processed on August first. Does that match what you expected?
306 1632
307- Identify as ACME Internet Support.1633### Common Tools
308- Keep it brief; invite the caller’s goal.
309 1634
310Sample phrases (vary, don’t always reuse):1635`gpt-realtime-1.5` has been trained to effectively use the following common tools. If your use case needs similar behavior, keep the names, signatures, and descriptions close to these to maximize reliability and to be more in-distribution.
311 1636
312- “Thanks for calling ACME Internet—how can I help today?”1637Below are some of the important common tools that the model has been trained on:
313- “You’ve reached ACME Support. What’s going on with your service?”1638
314- “Hi there—tell me what you’d like help with.”1639#### Example
315 1640
316Exit when: Caller states an initial goal or symptom.
317```1641```
1642# answer(question: string)
1643Description: Call this when the customer asks a question that you don't have an answer to or asks to perform an action.
318 1644
319#### 6. Avoid robotic repetition.
320 1645
321If responses sound repetitive or robotic, include an explicit variety instruction. This can sometimes happen when using sample phrases.1646# escalate_to_human()
1647Description: Call this when a customer asks for escalation, or to talk to someone else, or expresses dissatisfaction with the call.
322 1648
323```markdown
324## Variety
325 1649
326- Do not repeat the same sentence twice. Vary your responses so it doesn't sound robotic.1650# finish_session()
1651Description: Call this when a customer says they're done with the session or doesn't want to continue. If it's ambiguous, confirm with the customer before calling.
327```1652```
328 1653
329#### 7. Use capitalized text to emphasize instructions.1654## Conversation Flow
330 1655
331Like many LLMs, using capitalization for important rules can help the model to understand and follow those rules. It's also helpful to convert non-text rules (such as numerical conditions) into text before capitalization.1656This section covers how to structure the dialogue into clear, goal-driven phases so the model knows exactly what to do at each step. It defines the purpose of each phase, the instructions for moving through it, and the concrete “exit criteria” for transitioning to the next. This prevents the model from stalling, skipping steps, or jumping ahead, and ensures the conversation stays organized from greeting to resolution.
332 1657
333Instead of:1658As well, by organizing your prompt into various conversation states, it becomes easier to identify error modes and iterate more effectively.
334 1659
335```markdown1660- **When to use**: If conversations feel disorganized, stall before reaching the goal, or the model struggles to effectively complete the objective.
336## Rules1661- **What it does**: Breaks the interaction into phases with clear goals, instructions and exit criteria.
1662- **How to adapt**: Rename phases to match your workflow; modify instructions for each phase to follow your intended behavior; keep “Exit when” concrete and minimal.
1663
1664#### Example
337 1665
338- If [func.return_value] > 0, respond 1 to the user.
339```1666```
1667# Conversation Flow
1668## 1) Greeting
1669Goal: Set tone and invite the reason for calling.
1670How to respond:
1671- Identify as NorthLoop Internet Support.
1672- Keep the opener brief and invite the caller’s goal.
1673- Confirm that customer is a Northloop customer
1674Exit to Discovery: Caller states they are a Northloop customer and mentions an initial goal or symptom.
340 1675
341Use:
342 1676
343```markdown1677## 2) Discover
344## Rules1678Goal: Classify the issue and capture minimal details.
1679How to respond:
1680- Determine billing vs connectivity with one targeted question.
1681- For connectivity: collect the service address.
1682- For billing/account: collect email or phone used on the account.
1683Exit when: Intent and address (for connectivity) or email/phone (for billing) are known.
345 1684
346- IF [func.return_value] IS BIGGER THAN 0, RESPOND 1 TO THE USER.
347```
348 1685
349#### 8. Help the model use tools.1686## 3) Verify
1687Goal: Confirm identity and retrieve the account.
1688How to respond:
1689- Once you have email or phone, call lookup_account(email_or_phone).
1690- If lookup fails, try the alternate identifier once; otherwise proceed with general guidance or offer escalation if account actions are required.
1691Exit when: Account ID is returned.
1692
350 1693
351The model's use of tools can alter the experience—how much they rely on user confirmation vs. taking action, what they say while they make the tool call, which rules they follow for each specific tool, etc.1694## 4) Diagnose
1695Goal: Decide outage vs local issue.
1696How to respond:
1697- For connectivity, call check_outage(address).
1698- If outage=true, skip local steps; move to Resolve with outage context.
1699- If outage=false, guide a short reboot/cabling check; confirm each step’s result before continuing.
1700Exit when: Root cause known.
352 1701
353One way to prompt for tool usage is to use preambles. Good preambles instruct the model to give the user some feedback about what it's doing before it makes the tool call, so the user always knows what's going on.
354 1702
355Here's an example:1703## 5) Resolve
1704Goal: Apply fix, credit, or appointment.
1705How to respond:
1706- If confirmed outage > 240 minutes in the last 7 days, call refund_credit(account_id, 60).
1707- If outage=false and issue persists after basic checks, offer “10am–12pm ET” or “2pm–4pm ET” and call schedule_technician(account_id, chosen window).
1708- If the local fix worked, state the result and next steps briefly.
1709Exit when: A fix/credit/appointment has been applied and acknowledged by the caller.
356 1710
357```markdown
358# Tools
359 1711
360- Before any tool call, say one short line like “I’m checking that now.” Then call the tool immediately.1712## 6) Confirm/Close
1713Goal: Confirm outcome and end cleanly.
1714How to respond:
1715- Restate the result and any next step (e.g., stabilization window or tech ETA).
1716- Invite final questions; close politely if none.
1717Exit when: Caller declines more help.
361```1718```
362 1719
363You can include sample phrases for preambles to add variety and better tailor to your use case.1720### Sample Phrases
364 1721
365There are several other ways to improve the model's behavior when performing tool calls and keeping the conversation going with the user. Ideally, the model is calling the right tools proactively, checking for confirmation for any important write actions, and keeping the user informed along the way. For more specifics, see the [realtime prompting cookbook](https://developers.openai.com/cookbook/examples/realtime_prompting_guide).1722Sample phrases act as “anchor examples” for the model. They show the style, brevity, and tone you want it to follow, without locking it into one rigid response.
366 1723
367#### 9. Use LLMs to improve your prompt.1724- **When to use**: Responses lack your brand style or are not consistent.
1725- **What it does**: Provides sample phrases the model can vary to stay natural and brief.
1726- **How to adapt**: Swap examples for brand-fit; keep the “do not always use” warning.
368 1727
369LLMs are great at finding what's going wrong in your prompt. Use ChatGPT or the API to get a model's review of your current realtime prompt and get help improving it.1728#### Example
370 1729
371Whether your prompt is working well or not, here's a prompt you can run to get a model's review:1730```
1731# Sample Phrases
1732- Below are sample examples that you should use for inspiration. DO NOT ALWAYS USE THESE EXAMPLES, VARY YOUR RESPONSES.
1733
1734Acknowledgements: “On it.” “One moment.” “Good question.”
1735Clarifiers: “Do you want A or B?” “What’s the deadline?”
1736Bridges: “Here’s the quick plan.” “Let’s keep it simple.”
1737Empathy (brief): “That’s frustrating—let’s fix it.”
1738Closers: “Anything else before we wrap?” “Happy to help next time.”
1739```
372 1740
373```markdown1741_Note: If your voice system ends up consistently only repeating the sample phrases, leading to a more robotic voice experience, try adding the Variety constraint. We’ve seen this fix the issue._
374## Role & Objective
375 1742
376You are a **Prompt-Critique Expert**.1743### Conversation flow + Sample Phrases
377Examine a user-supplied LLM prompt and surface any weaknesses following the instructions below.
378 1744
379## Instructions1745It is a useful pattern to add sample phrases in the different conversation flow states to teach the model what a good response looks like:
380 1746
381Review the prompt that is meant for an LLM to follow and identify the following issues:1747#### Example
382 1748
383- Ambiguity: Could any wording be interpreted in more than one way?1749```
384- Lacking Definitions: Are there any class labels, terms, or concepts that are not defined that might be misinterpreted by an LLM?1750# Conversation Flow
385- Conflicting, missing, or vague instructions: Are directions incomplete or contradictory?1751## 1) Greeting
386- Unstated assumptions: Does the prompt assume the model has to be able to do something that is not explicitly stated?1752Goal: Set tone and invite the reason for calling.
1753How to respond:
1754- Identify as NorthLoop Internet Support.
1755- Keep the opener brief and invite the caller’s goal.
1756Sample phrases (do not always repeat the same phrases, vary your responses):
1757- “Thanks for calling NorthLoop Internet—how can I help today?”
1758- “You’ve reached NorthLoop Support. What’s going on with your service?”
1759- “Hi there—tell me what you’d like help with.”
1760Exit when: Caller states an initial goal or symptom.
387 1761
388## Do **NOT** list issues of the following types:
389 1762
390- Invent new instructions, tool calls, or external information. You do not know what tools need to be added that are missing.1763## 2) Discover
391- Issues that you are not sure about.1764Goal: Classify the issue and capture minimal details.
1765How to respond:
1766- Determine billing vs connectivity with one targeted question.
1767- For connectivity: collect the service address.
1768- For billing/account: collect email or phone used on the account.
1769Sample phrases (do not always repeat the same phrases, vary your responses):
1770- “Is this about your bill or your internet speed?”
1771- “What address are you using for the connection?”
1772- “What’s the email or phone number on the account?”
1773Exit when: Intent and address (for connectivity) or email/phone (for billing) are known.
1774
1775
1776## 3) Verify
1777Goal: Confirm identity and retrieve the account.
1778How to respond:
1779- Once you have email or phone, call lookup_account(email_or_phone).
1780- If lookup fails, try the alternate identifier once; otherwise proceed with general guidance or offer escalation if account actions are required.
1781Sample phrases:
1782- “Thanks—looking up your account now.”
1783- “If that doesn’t pull up, what’s the other contact—email or phone?”
1784- “Found your account. I’ll take care of this.”
1785Exit when: Account ID is returned.
392 1786
393## Output Format
394 1787
395# Issues1788## 4) Diagnose
1789Goal: Decide outage vs local issue.
1790How to respond:
1791- For connectivity, call check_outage(address).
1792- If outage=true, skip local steps; move to Resolve with outage context.
1793- If outage=false, guide a short reboot/cabling check; confirm each step’s result before continuing.
1794Sample phrases (do not always repeat the same phrases, vary your responses):
1795- “I’m running a quick outage check for your area.”
1796- “No outage reported—let’s try a fast modem reboot.”
1797- “Please confirm the modem lights: is the internet light solid or blinking?”
1798Exit when: Root cause known.
1799
1800
1801## 5) Resolve
1802Goal: Apply fix, credit, or appointment.
1803How to respond:
1804- If confirmed outage > 240 minutes in the last 7 days, call refund_credit(account_id, 60).
1805- If outage=false and issue persists after basic checks, offer “10am–12pm ET” or “2pm–4pm ET” and call schedule_technician(account_id, chosen window).
1806- If the local fix worked, state the result and next steps briefly.
1807Sample phrases (do not always repeat the same phrases, vary your responses):
1808- “There’s been an extended outage—adding a 60-minute bill credit now.”
1809- “No outage—let’s book a technician. I can do 10am–12pm ET or 2pm–4pm ET.”
1810- “Credit applied—you’ll see it on your next bill.”
1811Exit when: A fix/credit/appointment has been applied and acknowledged by the caller.
1812
1813
1814## 6) Confirm/Close
1815Goal: Confirm outcome and end cleanly.
1816How to respond:
1817- Restate the result and any next step (e.g., stabilization window or tech ETA).
1818- Invite final questions; close politely if none.
1819Sample phrases (do not always repeat the same phrases, vary your responses):
1820- “We’re all set: [credit applied / appointment booked / service restored].”
1821- “You should see stable speeds within a few minutes.”
1822- “Your technician window is 10am–12pm ET.”
1823Exit when: Caller declines more help.
396 1824
397- Numbered list; include brief quote snippets.1825```
398 1826
399# Improvements1827### Advanced Conversation Flow
400 1828
401- Numbered list; provide the revised lines you would change and how you would changed them.1829As use cases grow more complex, you’ll need a structure that scales while keeping the model effective. The key is balancing maintainability with simplicity: too many rigid states can overload the model, hurting performance and making conversations feel robotic.
402 1830
403# Revised Prompt1831A better approach is to design flows that reduce the model’s perceived complexity. By handling state in a structured but flexible way, you make it easier for the model to stay focused and responsive, which improves user experience.
404 1832
405- Revised prompt where you have applied all your improvements surgically with minimal edits to the original prompt1833Two common patterns for managing complex scenarios are:
406```
407 1834
408Use this template as a starting point for troubleshooting a recurring issue:18351. Conversation Flow as State Machine
18362. Dynamic Conversation Flow via session.updates
409 1837
410```markdown1838#### Conversation Flow as State Machine
411Here's my current prompt to an LLM:
412[BEGIN OF CURRENT PROMPT]
413{CURRENT_PROMPT}
414[END OF CURRENT PROMPT]
415 1839
416But I see this issue happening from the LLM:1840Define your conversation as a JSON structure that encodes both states and transitions. This makes it easy to reason about coverage, identify edge cases, and track changes over time. Since it’s stored as code, you can version, diff, and extend it as your flow evolves. A state machine also gives you fine-grained control over exactly how and when the conversation moves from one state to another.
417[BEGIN OF ISSUE]1841
418{ISSUE}1842#### Example
419[END OF ISSUE]1843
420Can you provide some variants of the prompt so that the model can better understand the constraints to alleviate the issue?1844```json
1845# Conversation States
1846[
1847 {
1848 "id": "1_greeting",
1849 "description": "Begin each conversation with a warm, friendly greeting, identifying the service and offering help.",
1850 "instructions": [
1851 "Use the company name 'Snowy Peak Boards' and provide a warm welcome.",
1852 "Let them know upfront that for any account-specific assistance, you’ll need some verification details."
1853 ],
1854 "examples": [
1855 "Hello, this is Snowy Peak Boards. Thanks for reaching out! How can I help you today?"
1856 ],
1857 "transitions": [{
1858 "next_step": "2_get_first_name",
1859 "condition": "Once greeting is complete."
1860 }, {
1861 "next_step": "3_get_and_verify_phone",
1862 "condition": "If the user provides their first name."
1863 }]
1864 },
1865 {
1866 "id": "2_get_first_name",
1867 "description": "Ask for the user’s name (first name only).",
1868 "instructions": [
1869 "Politely ask, 'Who do I have the pleasure of speaking with?'",
1870 "Do NOT verify or spell back the name; just accept it."
1871 ],
1872 "examples": [
1873 "Who do I have the pleasure of speaking with?"
1874 ],
1875 "transitions": [{
1876 "next_step": "3_get_and_verify_phone",
1877 "condition": "Once name is obtained, OR name is already provided."
1878 }]
1879 },
1880 {
1881 "id": "3_get_and_verify_phone",
1882 "description": "Request phone number and verify by repeating it back.",
1883 "instructions": [
1884 "Politely request the user’s phone number.",
1885 "Once provided, confirm it by repeating each digit and ask if it’s correct.",
1886 "If the user corrects you, confirm AGAIN to make sure you understand.",
1887 ],
1888 "examples": [
1889 "I'll need some more information to access your account if that's okay. May I have your phone number, please?",
1890 "You said 0-2-1-5-5-5-1-2-3-4, correct?",
1891 "You said 4-5-6-7-8-9-0-1-2-3, correct?"
1892 ],
1893 "transitions": [{
1894 "next_step": "4_authentication_DOB",
1895 "condition": "Once phone number is confirmed"
1896 }]
1897 },
1898...
421```1899```
422 1900
423#### 10. Help users resolve issues faster.1901#### Dynamic Conversation Flow
424 1902
425Two frustrating user experiences are slow, mechanical voice agents and the inability to escalate. Help users faster by providing instructions in your system prompt for speed and escalation.1903In this pattern, the conversation adapts in real time by updating the system prompt and tool list based on the current state. Instead of exposing the model to all possible rules and tools at once, you only provide what’s relevant to the active phase of the conversation.
426 1904
427In the personality and tone section of your system prompt, add pacing instructions to get the model to quicken its support:1905When the end conditions for a state are met, you use session.update to transition, replacing the prompt and tools with those needed for the next phase.
428 1906
429```markdown1907This approach reduces the model’s cognitive load, making it easier for it to handle complex tasks without being distracted by unnecessary context.
430# Personality & Tone
431 1908
432## Personality1909#### Example
433 1910
434Friendly, calm and approachable expert customer service assistant.1911```python
1912from typing import Dict, List, Literal
435 1913
436## Tone1914State = Literal["verify", "resolve"]
437 1915
438Tone: Warm, concise, confident, never fawning.1916# Allowed transitions
1917TRANSITIONS: Dict[State, List[State]] = {
1918 "verify": ["resolve"],
1919 "resolve": [] # terminal
1920}
439 1921
440## Length1922def build_state_change_tool(current: State) -> dict:
1923 allowed = TRANSITIONS[current]
1924 readable = ", ".join(allowed) if allowed else "no further states (terminal)"
1925 return {
1926 "type": "function",
1927 "name": "set_conversation_state",
1928 "description": (
1929 f"Switch the conversation phase. Current: '{current}'. "
1930 f"You may switch only to: {readable}. "
1931 "Call this AFTER exit criteria are satisfied."
1932 ),
1933 "parameters": {
1934 "type": "object",
1935 "properties": {
1936 "next_state": {"type": "string", "enum": allowed}
1937 },
1938 "required": ["next_state"]
1939 }
1940 }
441 1941
4422–3 sentences per turn.1942# Minimal business tools per state
1943TOOLS_BY_STATE: Dict[State, List[dict]] = {
1944 "verify": [{
1945 "type": "function",
1946 "name": "lookup_account",
1947 "description": "Fetch account by email or phone.",
1948 "parameters": {
1949 "type": "object",
1950 "properties": {"email_or_phone": {"type": "string"}},
1951 "required": ["email_or_phone"]
1952 }
1953 }],
1954 "resolve": [{
1955 "type": "function",
1956 "name": "schedule_technician",
1957 "description": "Book a technician visit.",
1958 "parameters": {
1959 "type": "object",
1960 "properties": {
1961 "account_id": {"type": "string"},
1962 "window": {"type": "string", "enum": ["10-12 ET", "14-16 ET"]}
1963 },
1964 "required": ["account_id", "window"]
1965 }
1966 }]
1967}
443 1968
444## Pacing1969# Short, phase-specific instructions
1970INSTRUCTIONS_BY_STATE: Dict[State, str] = {
1971 "verify": (
1972 "# Role & Objective\n"
1973 "Verify identity to access the account.\n\n"
1974 "# Conversation (Verify)\n"
1975 "- Ask for the email or phone on the account.\n"
1976 "- Read back digits one-by-one (e.g., '4-1-5… Is that correct?').\n"
1977 "Exit when: Account ID is returned.\n"
1978 "When exit is satisfied: call set_conversation_state(next_state=\"resolve\")."
1979 ),
1980 "resolve": (
1981 "# Role & Objective\n"
1982 "Apply a fix by booking a technician.\n\n"
1983 "# Conversation (Resolve)\n"
1984 "- Offer two windows: '10–12 ET' or '2–4 ET'.\n"
1985 "- Book the chosen window.\n"
1986 "Exit when: Appointment is confirmed.\n"
1987 "When exit is satisfied: end the call politely."
1988 )
1989}
445 1990
446Deliver your audio response fast, but do not sound rushed. Do not modify the content of your response, only increase speaking speed for the same response.1991def build_session_update(state: State) -> dict:
1992 """Return the JSON payload for a Realtime `session.update` event."""
1993 return {
1994 "type": "session.update",
1995 "session": {
1996 "instructions": INSTRUCTIONS_BY_STATE[state],
1997 "tools": TOOLS_BY_STATE[state] + [build_state_change_tool(state)]
1998 }
1999 }
447```2000```
448 2001
449Often with realtime voice agents, having a reliable way to escalate to a human is important. In a safety and escalation section, modify the instructions on WHEN to escalate depending on your use case. Here's an example:2002## Safety & Escalation
450 2003
451```markdown2004Often with Realtime voice agents, having a reliable way to escalate to a human is important. In this section, you should modify the instructions on WHEN to escalate depending on your use case.
452# Safety & Escalation
453 2005
454When to escalate (no extra troubleshooting):2006- **When to use**: Model is struggling to determine when to properly escalate to a human or fallback system
2007- **What it does**: Defines fast, reliable escalation and what to say.
2008- **How to adapt**: Insert your own thresholds and what the model has to say.
2009
2010#### Example
455 2011
2012```
2013# Safety & Escalation
2014When to escalate (no extra troubleshooting):
456- Safety risk (self-harm, threats, harassment)2015- Safety risk (self-harm, threats, harassment)
457- User explicitly asks for a human2016- User explicitly asks for a human
458- Severe dissatisfaction (e.g., “extremely frustrated,” repeated complaints, profanity)2017- Severe dissatisfaction (e.g., “extremely frustrated,” repeated complaints, profanity)
459- **2** failed tool attempts on the same task **or** **3** consecutive no-match/no-input events2018- **2** failed tool attempts on the same task **or** **3** consecutive no-match/no-input events
460- Out-of-scope or restricted (e.g., real-time news, financial/legal/medical advice)2019- Out-of-scope or restricted (e.g., real-time news, financial/legal/medical advice)
461 2020
462What to say at the same time of calling the escalate_to_human tool (MANDATORY):2021What to say at the same time as calling the escalate_to_human tool (MANDATORY):
463 2022- “Thanks for your patience—I’m connecting you with a specialist now.”
464- “Thanks for your patience—**I’m connecting you with a specialist now**.”
465- Then call the tool: `escalate_to_human`2023- Then call the tool: `escalate_to_human`
466 2024
467Examples that would require escalation:2025Examples that would require escalation:
470- “I am extremely frustrated!”2027- “I am extremely frustrated!”
471```2028```
472 2029
473## Further reading2030The first example shows conversation responses from `gpt-4o-realtime-preview-2025-06-03` using the instruction.
2031
2032
2033
2034The second example shows conversation responses from `gpt-realtime-1.5` using the instruction.
2035
2036
2037
2038`gpt-realtime-1.5` is able to follow the instruction and escalate to a human more reliably.
2039
2040 </div>
2041
2042
474 2043
475This guide is long but not exhaustive! For more in a specific area, see the following resources:2044## Next steps
476 2045
477- [Realtime prompting cookbook](https://developers.openai.com/cookbook/examples/realtime_prompting_guide): Full prompt examples and a deep dive into when and how to use them2046- Review the earlier [Realtime prompting guide](https://developers.openai.com/cookbook/examples/realtime_prompting_guide) for more `gpt-realtime-1.5` examples.
478- [Inputs and outputs](https://developers.openai.com/api/docs/guides/realtime-inputs-outputs): Text and audio input requirements and output options2047- Review the [Realtime eval guide](https://developers.openai.com/cookbook/examples/realtime_eval_guide) to test representative voice-agent behavior.
479- [Managing conversations](https://developers.openai.com/api/docs/guides/realtime-conversations): Learn to manage a conversation for the duration of a realtime session2048- Learn how to connect with [WebRTC](https://developers.openai.com/api/docs/guides/realtime-webrtc), [WebSocket](https://developers.openai.com/api/docs/guides/realtime-websocket), or [SIP](https://developers.openai.com/api/docs/guides/realtime-sip).
480- [Webhooks and server-side controls](https://developers.openai.com/api/docs/guides/realtime-server-controls): Create a sideband channel to separate sensitive server-side logic from an untrusted client2049- Learn the [Realtime conversation lifecycle](https://developers.openai.com/api/docs/guides/realtime-conversations).
481- [Managing costs](https://developers.openai.com/api/docs/guides/realtime-costs): Understand how costs are calculated and strategies to optimize them2050- Review [Realtime costs](https://developers.openai.com/api/docs/guides/realtime-costs).
482- [Function calling](https://developers.openai.com/api/docs/guides/realtime-function-calling): How to call functions in your realtime app
483- [MCP servers](https://developers.openai.com/api/docs/guides/realtime-mcp): How to use MCP servers to access additional tools in realtime apps
484- [Realtime transcription](https://developers.openai.com/api/docs/guides/realtime-transcription): How to transcribe audio with the Realtime API
485- [Voice agents](https://developers.openai.com/api/docs/guides/voice-agents): A guide for building voice agents with the Agents SDK
