1# Voice agents1# Voice agents
2 2
3import {3Voice agents turn the same agent concepts into spoken, low-latency interactions. The key design choice is deciding whether the model should work directly with live audio or whether your application should explicitly chain speech-to-text, text reasoning, and text-to-speech.
4 TextToSpeech,
5 CaretRight,
6 Text,
7 Wave,
8 Voice,
9} from "@components/react/oai/platform/ui/Icon.react";
10import {
11 speechToSpeechIcon,
12 chainedIcon,
13} from "@components/react/guides/VoiceAgentIcons.react";
14
15
16
17
18
19
20
21Use the OpenAI API and Agents SDK to create powerful, context-aware voice agents for applications like customer support and language tutoring. This guide helps you design and build a voice agent.
22 4
23## Choose the right architecture5## Choose the right architecture
24 6
25OpenAI provides two primary architectures for building voice agents:7| Architecture | Best for | Why |
26 8| ----------------------------------------- | --------------------------------------------------------- | ------------------------------------------------------------------------------------- |
27### Speech-to-speech (realtime) architecture9| Speech-to-speech with live audio sessions | Natural, low-latency conversations | The model handles live audio input and output directly |
28 10| Chained voice pipeline | Predictable workflows or extending an existing text agent | Your app keeps explicit control over transcription, text reasoning, and speech output |
29
30
31The multimodal speech-to-speech (S2S) architecture directly processes audio inputs and outputs, handling speech in real time in a single multimodal model, `gpt-4o-realtime-preview`. The model thinks and responds in speech. It doesn't rely on a transcript of the user's input—it hears emotion and intent, filters out noise, and responds directly in speech. Use this approach for highly interactive, low-latency, conversational use cases.
32
33| Strengths | Best for |
34| ------------------------------------------------------------- | ------------------------------------------------------ |
35| Low latency interactions | Interactive and unstructured conversations |
36| Rich multimodal understanding (audio and text simultaneously) | Language tutoring and interactive learning experiences |
37| Natural, fluid conversational flow | Conversational search and discovery |
38| Enhanced user experience through vocal context understanding | Interactive customer service scenarios |
39
40### Chained architecture
41
42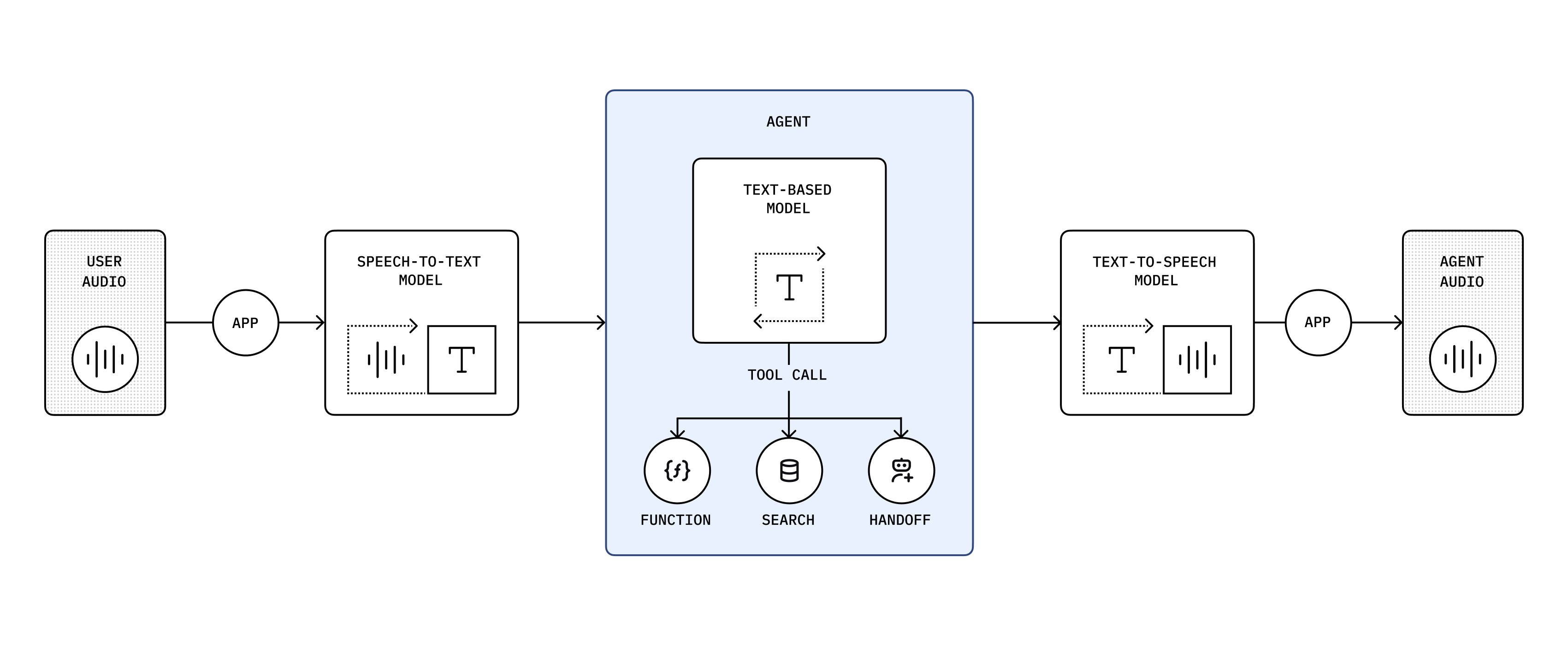
43
44A chained architecture processes audio sequentially, converting audio to text, generating intelligent responses using large language models (LLMs), and synthesizing audio from text. We recommend this predictable architecture if you're new to building voice agents. Both the user input and model's response are in text, so you have a transcript and can control what happens in your application. It's also a reliable way to convert an existing LLM-based application into a voice agent.
45
46You're chaining these models: `gpt-4o-transcribe` → `gpt-4.1` → `gpt-4o-mini-tts`
47
48| Strengths | Best for |
49| --------------------------------------------------- | --------------------------------------------------------- |
50| High control and transparency | Structured workflows focused on specific user objectives |
51| Robust function calling and structured interactions | Customer support |
52| Reliable, predictable responses | Sales and inbound triage |
53| Support for extended conversational context | Scenarios that involve transcripts and scripted responses |
54
55
56The following guide below is for building agents using our recommended **speech-to-speech architecture**.<br/><br/>
57
58To learn more about the chained architecture, see [the chained architecture guide](https://developers.openai.com/api/docs/guides/voice-agents?voice-agent-architecture=chained).
59
60
61
62
63## Build a voice agent
64
65Use OpenAI's APIs and SDKs to create powerful, context-aware voice agents.
66
67
68Building a speech-to-speech voice agent requires:
69
701. Establishing a connection for realtime data transfer
712. Creating a realtime session with the Realtime API
723. Using an OpenAI model with realtime audio input and output capabilities
73
74If you are new to building voice agents, we recommend using the [Realtime Agents in the TypeScript Agents SDK](https://openai.github.io/openai-agents-js/guides/voice-agents/) to get started with your voice agents.
75
76```bash
77npm install @openai/agents
78```
79
80If you want to get an idea of what interacting with a speech-to-speech voice agent looks like, check
81out our [quickstart guide](https://openai.github.io/openai-agents-js/guides/voice-agents/) to get started or check out our example application below.
82
83<a
84 href="https://github.com/openai/openai-realtime-agents"
85 target="_blank"
86 rel="noreferrer"
87>
88
89
90<span slot="icon">
91 </span>
92 A collection of example speech-to-speech voice agents including handoffs and
93 reasoning model validation.
94 11
12Agent Builder doesn't currently support voice workflows, so voice stays an SDK-first surface.
95 13
96</a>14## Recommended starting points
97 15
98### Choose your transport method16The two supported languages expose different strengths today:
99 17
100As latency is critical in voice agent use cases, the Realtime API provides two low-latency18- In TypeScript, the fastest path to a browser-based voice assistant is a `RealtimeAgent` and `RealtimeSession`.
101transport methods:19- In Python, the simplest path to extending an existing text agent into voice is a chained `VoicePipeline`.
102 20
1031. **WebRTC**: A peer-to-peer protocol that allows for low-latency audio and video communication.21Two common voice starting points
1042. **WebSocket**: A common protocol for realtime data transfer.
105 22
106The two transport methods for the Realtime API support largely the same capabilities, but which one23```typescript
107is more suitable for you will depend on your use case.24import { RealtimeAgent, RealtimeSession } from "@openai/agents/realtime";
108
109WebRTC is generally the better choice if you are building client-side applications such as
110browser-based voice agents.
111
112For anything where you are executing the agent server-side such as building an agent that can
113[answer phone calls](https://github.com/openai/openai-realtime-twilio-demo), WebSockets will be the
114better option.
115
116If you are using the [OpenAI Agents SDK for TypeScript](https://openai.github.io/openai-agents-js/),
117we will automatically use WebRTC if you are building in the browser and WebSockets otherwise.
118
119### Design your voice agent
120
121Just like when designing a text-based agent, you'll want to start small and keep your agent focused
122on a single task.
123
124Try to limit the number of tools your agent has access to and provide an escape hatch for the agent
125to deal with tasks that it is not equipped to handle.
126
127This could be a tool that allows the agent to handoff the conversation to a human or a certain
128phrase that it can fall back to.
129
130While providing tools to text-based agents is a great way to provide additional context to the
131agent, for voice agents you should consider giving critical information as part of the prompt as
132opposed to requiring the agent to call a tool first.
133
134If you are just getting started, check out our [Realtime Playground](https://platform.openai.com/playground/realtime) that
135provides prompt generation helpers, as well as a way to stub out your function tools including
136stubbed tool responses to try end to end flows.
137
138### Precisely prompt your agent
139 25
140With speech-to-speech agents, prompting is even more powerful than with text-based agents as the26const agent = new RealtimeAgent({
141prompt allows you to not just control the content of the agent's response but also the way the agent27 name: "Assistant",
142speaks or help it understand audio content.28 instructions: "You are a helpful voice assistant.",
29});
143 30
144A good example of what a prompt might look like:31const session = new RealtimeSession(agent, {
32 model: "gpt-realtime-1.5",
33});
145 34
35await session.connect({
36 apiKey: "ek_...(ephemeral key from your server)",
37});
146```38```
147# Personality and Tone
148## Identity
149// Who or what the AI represents (e.g., friendly teacher, formal advisor, helpful assistant). Be detailed and include specific details about their character or backstory.
150 39
151## Task40```python
152// At a high level, what is the agent expected to do? (e.g. "you are an expert at accurately handling user returns")41import asyncio
42import numpy as np
153 43
154## Demeanor44from agents import Agent, function_tool
155// Overall attitude or disposition (e.g., patient, upbeat, serious, empathetic)45from agents.voice import AudioInput, SingleAgentVoiceWorkflow, VoicePipeline
156 46
157## Tone
158// Voice style (e.g., warm and conversational, polite and authoritative)
159 47
160## Level of Enthusiasm48@function_tool
161// Degree of energy in responses (e.g., highly enthusiastic vs. calm and measured)49def get_weather(city: str) -> str:
50 """Get the weather for a given city."""
51 return f"The weather in {city} is sunny."
162 52
163## Level of Formality
164// Casual vs. professional language (e.g., “Hey, great to see you!” vs. “Good afternoon, how may I assist you?”)
165 53
166## Level of Emotion54agent = Agent(
167// How emotionally expressive or neutral the AI should be (e.g., compassionate vs. matter-of-fact)55 name="Assistant",
56 instructions="You are a helpful voice assistant.",
57 model="gpt-5.4",
58 tools=[get_weather],
59)
168 60
169## Filler Words
170// Helps make the agent more approachable, e.g. “um,” “uh,” "hm," etc.. Options are generally "none", "occasionally", "often", "very often"
171 61
172## Pacing62async def main() -> None:
173// Rhythm and speed of delivery63 pipeline = VoicePipeline(workflow=SingleAgentVoiceWorkflow(agent))
64 audio_input = AudioInput(buffer=np.zeros(24000 * 3, dtype=np.int16))
65 result = await pipeline.run(audio_input)
66 async for event in result.stream():
67 if event.type == "voice_stream_event_audio":
68 print("Received audio bytes", len(event.data))
174 69
175## Other details
176// Any other information that helps guide the personality or tone of the agent.
177 70
178# Instructions71if __name__ == "__main__":
179- If a user provides a name or phone number, or something else where you need to know the exact spelling, always repeat it back to the user to confirm you have the right understanding before proceeding. // Always include this72 asyncio.run(main())
180- If the caller corrects any detail, acknowledge the correction in a straightforward manner and confirm the new spelling or value.
181```73```
182 74
183You do not have to be as detailed with your instructions. This is for illustrative purposes. For
184shorter examples, check out the prompts on [OpenAI.fm](https://openai.fm).
185 75
186For use cases with common conversation flows you can encode those inside the prompt using markup language like JSON76<span id="speech-to-speech-realtime-architecture"></span>
187 77
188```78## Build a speech-to-speech voice agent
189# Conversation States
190[
191 {
192 "id": "1_greeting",
193 "description": "Greet the caller and explain the verification process.",
194 "instructions": [
195 "Greet the caller warmly.",
196 "Inform them about the need to collect personal information for their record."
197 ],
198 "examples": [
199 "Good morning, this is the front desk administrator. I will assist you in verifying your details.",
200 "Let us proceed with the verification. May I kindly have your first name? Please spell it out letter by letter for clarity."
201 ],
202 "transitions": [{
203 "next_step": "2_get_first_name",
204 "condition": "After greeting is complete."
205 }]
206 },
207 {
208 "id": "2_get_first_name",
209 "description": "Ask for and confirm the caller's first name.",
210 "instructions": [
211 "Request: 'Could you please provide your first name?'",
212 "Spell it out letter-by-letter back to the caller to confirm."
213 ],
214 "examples": [
215 "May I have your first name, please?",
216 "You spelled that as J-A-N-E, is that correct?"
217 ],
218 "transitions": [{
219 "next_step": "3_get_last_name",
220 "condition": "Once first name is confirmed."
221 }]
222 },
223 {
224 "id": "3_get_last_name",
225 "description": "Ask for and confirm the caller's last name.",
226 "instructions": [
227 "Request: 'Thank you. Could you please provide your last name?'",
228 "Spell it out letter-by-letter back to the caller to confirm."
229 ],
230 "examples": [
231 "And your last name, please?",
232 "Let me confirm: D-O-E, is that correct?"
233 ],
234 "transitions": [{
235 "next_step": "4_next_steps",
236 "condition": "Once last name is confirmed."
237 }]
238 },
239 {
240 "id": "4_next_steps",
241 "description": "Attempt to verify the caller's information and proceed with next steps.",
242 "instructions": [
243 "Inform the caller that you will now attempt to verify their information.",
244 "Call the 'authenticateUser' function with the provided details.",
245 "Once verification is complete, transfer the caller to the tourGuide agent for further assistance."
246 ],
247 "examples": [
248 "Thank you for providing your details. I will now verify your information.",
249 "Attempting to authenticate your information now.",
250 "I'll transfer you to our agent who can give you an overview of our facilities. Just to help demonstrate different agent personalities, she's instructed to act a little crabby."
251 ],
252 "transitions": [{
253 "next_step": "transferAgents",
254 "condition": "Once verification is complete, transfer to tourGuide agent."
255 }]
256 }
257]
258```
259 79
260Instead of writing this out by hand, you can also check out this80Use the live audio API path when the interaction should feel conversational and immediate. The usual browser flow is:
261[Voice Agent Metaprompter](https://chatgpt.com/g/g-678865c9fb5c81918fa28699735dd08e-voice-agent-metaprompt-gpt)
262or [copy the metaprompt](https://github.com/openai/openai-realtime-agents/blob/main/src/app/agentConfigs/voiceAgentMetaprompt.txt) and use it directly.
263 81
264### Handle agent handoff821. Your application server creates an ephemeral client secret for the live audio session.
832. Your frontend creates a `RealtimeSession`.
843. The session connects over WebRTC in the browser or WebSocket on the server.
854. The agent handles audio turns, tools, interruptions, and handoffs inside that session.
265 86
266In order to keep your agent focused on a single task, you can provide the agent with the ability to87Start with the transport docs when you need lower-level control:
267transfer or handoff to another specialized agent. You can do this by providing the agent with a
268function tool to initiate the transfer. This tool should have information on when to use it for a
269handoff.
270 88
271If you are using the [OpenAI Agents SDK for TypeScript](https://openai.github.io/openai-agents-js/),89- [Live audio API overview](https://developers.openai.com/api/docs/guides/realtime)
272you can define any agent as a potential handoff to another agent.90- [Live audio API with WebRTC](https://developers.openai.com/api/docs/guides/realtime-webrtc)
91- [Live audio API with WebSocket](https://developers.openai.com/api/docs/guides/realtime-websocket)
273 92
274```typescript93## Build a chained voice workflow
275 94
95Use the chained path when you want stronger control over intermediate text, existing text-agent reuse, or a simpler extension path from a non-voice workflow. In that design, your application explicitly manages:
276 96
277const productSpecialist = new RealtimeAgent({971. speech-to-text
278 name: "Product Specialist",982. the agent workflow itself
279 instructions:993. text-to-speech
280 "You are a product specialist. You are responsible for answering questions about our products.",
281});
282
283const triageAgent = new RealtimeAgent({
284 name: "Triage Agent",
285 instructions:
286 "You are a customer service frontline agent. You are responsible for triaging calls to the appropriate agent.",
287 tools: [productSpecialist],
288});
289```
290
291The SDK will automatically facilitate the handoff between the agents for you.
292
293Alternatively if you are building your own voice agent, here is an example of such a tool definition:
294
295```js
296const tool = {
297 type: "function",
298 function: {
299 name: "transferAgents",
300 description: `
301Triggers a transfer of the user to a more specialized agent.
302Calls escalate to a more specialized LLM agent or to a human agent, with additional context.
303Only call this function if one of the available agents is appropriate. Don't transfer to your own agent type.
304
305Let the user know you're about to transfer them before doing so.
306
307Available Agents:
308- returns_agent
309- product_specialist_agent
310 `.trim(),
311 parameters: {
312 type: "object",
313 properties: {
314 rationale_for_transfer: {
315 type: "string",
316 description: "The reasoning why this transfer is needed.",
317 },
318 conversation_context: {
319 type: "string",
320 description:
321 "Relevant context from the conversation that will help the recipient perform the correct action.",
322 },
323 destination_agent: {
324 type: "string",
325 description:
326 "The more specialized destination_agent that should handle the user's intended request.",
327 enum: ["returns_agent", "product_specialist_agent"],
328 },
329 },
330 },
331 },
332};
333```
334
335Once the agent calls that tool you can then use the `session.update` event of the Realtime API to
336update the configuration of the session to use the instructions and tools available to the
337specialized agent.
338
339### Extend your agent with specialized models
340 100
341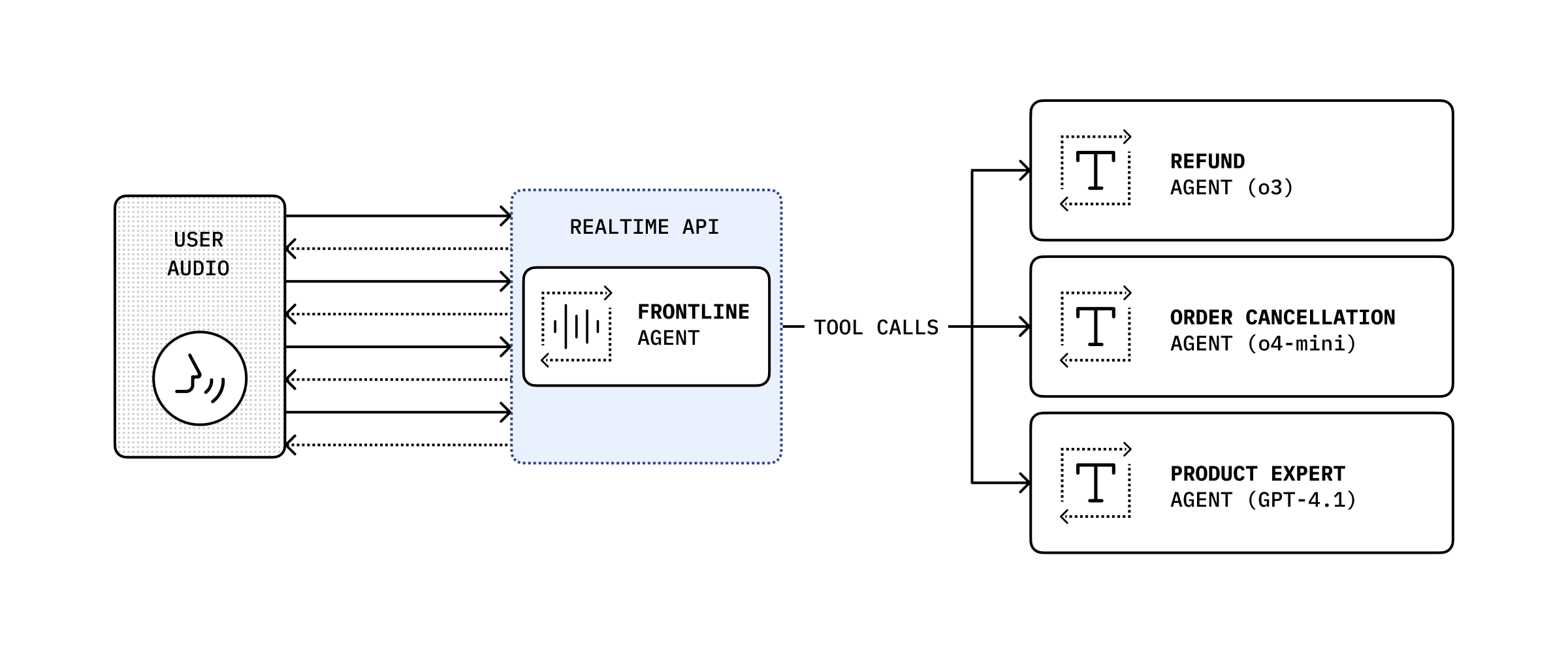101This is often the better fit for support flows, approval-heavy flows, or cases where you want durable transcripts and deterministic logic between each stage.
342 102
343While the speech-to-speech model is useful for conversational use cases, there might be use cases103## Voice agents still use the same core agent building blocks
344where you need a specific model to handle the task like having o3 validate a return request against
345a detailed return policy.
346 104
347In that case you can expose your text-based agent using your preferred model as a function tool105The voice surface changes the transport and audio loop, but the core workflow decisions are the same:
348call that your agent can send specific requests to.
349 106
350If you are using the [OpenAI Agents SDK for TypeScript](https://openai.github.io/openai-agents-js/),107- Use [Using tools](https://developers.openai.com/api/docs/guides/tools#usage-in-the-agents-sdk) when the voice agent needs external capabilities.
351you can give a `RealtimeAgent` a `tool` that will trigger the specialized agent on your server.108- Use [Running agents](https://developers.openai.com/api/docs/guides/agents/running-agents) when spoken workflows need streaming, continuation, or durable state.
109- Use [Orchestration and handoffs](https://developers.openai.com/api/docs/guides/agents/orchestration) when spoken workflows branch across specialists.
110- Use [Guardrails and human review](https://developers.openai.com/api/docs/guides/agents/guardrails-approvals) when spoken workflows need safety checks or approvals.
111- Use [Integrations and observability](https://developers.openai.com/api/docs/guides/agents/integrations-observability) when you need MCP-backed capabilities or want to inspect how the voice workflow behaved.
352 112
353```typescript
354
355
356
357const supervisorAgent = tool({
358 name: "supervisorAgent",
359 description: "Passes a case to your supervisor for approval.",
360 parameters: z.object({
361 caseDetails: z.string(),
362 }),
363 execute: async ({ caseDetails }, details) => {
364 const history = details.context.history;
365 const response = await fetch("/request/to/your/specialized/agent", {
366 method: "POST",
367 body: JSON.stringify({
368 caseDetails,
369 history,
370 }),
371 });
372 return response.text();
373 },
374});
375
376const returnsAgent = new RealtimeAgent({
377 name: "Returns Agent",
378 instructions:
379 "You are a returns agent. You are responsible for handling return requests. Always check with your supervisor before making a decision.",
380 tools: [supervisorAgent],
381});
382```
113The practical rule is: choose the audio architecture first, then design the rest of the agent workflow the same way you would for text.
